
I’m back from Amplitudes 2022 with more time to write, and (besides the several papers I’m working on) that means writing about the conference! Casual readers be warned, there’s no way around this being a technical post, I don’t have the space to explain everything!
I mostly said all I wanted about the way the conference was set up in last week’s post, but one thing I didn’t say much about was the conference dinner. Most conference dinners are the same aside from the occasional cool location or haggis speech. This one did have a cool location, and a cool performance by a blind pianist, but the thing I really wanted to comment on was the setup. Typically, the conference dinner at Amplitudes is a sit-down affair: people sit at tables in one big room, maybe getting up occasionally to pick up food, and eventually someone gives an after-dinner speech. This time the tables were standing tables, spread across several rooms. This was a bit tiring on a hot day, but it did have the advantage that it naturally mixed people around. Rather than mostly talking to “your table”, you’d wander, ending up at a new table every time you picked up new food or drinks. It was a good way to meet new people, a surprising number of which in my case apparently read this blog. It did make it harder to do an after-dinner speech, so instead Lance gave an after-conference speech, complete with the now-well-established running joke where Greta Thunberg tries to get us to fly less.
(In another semi-running joke, the organizers tried to figure out who had attended the most of the yearly Amplitudes conferences over the years. Weirdly, no-one has attended all twelve.)
In terms of the content, and things that stood out:
Nima is getting close to publishing his newest ‘hedron, the surfacehedron, and correspondingly was able to give a lot more technical detail about it. (For his first and most famous amplituhedron, see here.) He still didn’t have enough time to explain why he has to use category theory to do it, but at least he was concrete enough that it was reasonably clear where the category theory was showing up. (I wasn’t there for his eight-hour lecture at the school the week before, maybe the students who stuck around until 2am learned some category theory there.) Just from listening in on side discussions, I got the impression that some of the ideas here actually may have near-term applications to computing Feynman diagrams: this hasn’t been a feature of previous ‘hedra and it’s an encouraging development.
Alex Edison talked about progress towards this blog’s namesake problem, the question of whether N=8 supergravity diverges at seven loops. Currently they’re working at six loops on the N=4 super Yang-Mills side, not yet in a form it can be “double-copied” to supergravity. The tools they’re using are increasingly sophisticated, including various slick tricks from algebraic geometry. They are looking to the future: if they’re hoping their methods will reach seven loops, the same methods have to make six loops a breeze.
Xi Yin approached a puzzle with methods from String Field Theory, prompting the heretical-for-us title “on-shell bad, off-shell good”. A colleague reminded me of a local tradition for dealing with heretics.
While Nima was talking about a new ‘hedron, other talks focused on the original amplituhedron. Paul Heslop found that the amplituhedron is not literally a positive geometry, despite slogans to the contrary, but what it is is nonetheless an interesting generalization of the concept. Livia Ferro has made more progress on her group’s momentum amplituhedron: previously only valid at tree level, they now have a picture that can accomodate loops. I wasn’t sure this would be possible, there are a lot of things that work at tree level and not for loops, so I’m quite encouraged that this one made the leap successfully.
Sebastian Mizera, Andrew McLeod, and Hofie Hannesdottir all had talks that could be roughly summarized as “deep principles made surprisingly useful”. Each took topics that were explored in the 60’s and translated them into concrete techniques that could be applied to modern problems. There were surprisingly few talks on the completely concrete end, on direct applications to collider physics. I think Simone Zoia’s was the only one to actually feature collider data with error bars, which might explain why I singled him out to ask about those error bars later.
Likewise, Matthias Wilhelm’s talk was the only one on functions beyond polylogarithms, the elliptic functions I’ve also worked on recently. I wonder if the under-representation of some of these topics is due to the existence of independent conferences: in a year when in-person conferences are packed in after being postponed across the pandemic, when there are already dedicated conferences for elliptics and practical collider calculations, maybe people are just a bit too tired to go to Amplitudes as well.
Talks on gravitational waves seem to have stabilized at roughly a day’s worth, which seems reasonable. While the subfield’s capabilities continue to be impressive, it’s also interesting how often new conceptual challenges appear. It seems like every time a challenge to their results or methods is resolved, a new one shows up. I don’t know whether the field will ever get to a stage of “business as usual”, or whether it will be novel qualitative questions “all the way up”.
I haven’t said much about the variety of talks bounding EFTs and investigating their structure, though this continues to be an important topic. And I haven’t mentioned Lance Dixon’s talk on antipodal duality, largely because I’m planning a post on it later: Quanta Magazine had a good article on it, but there are some aspects even Quanta struggled to cover, and I think I might have a good way to do it.



 . It looks like three types of things, like three berries: five
. It looks like three types of things, like three berries: five  , six
, six  , and eight
, and eight  . Add another polynomial, and the illusion continues: add
. Add another polynomial, and the illusion continues: add 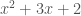 and you get
and you get  . You’ve just added more
. You’ve just added more  . That’s the same thing, you can check. But now it looks like five
. That’s the same thing, you can check. But now it looks like five 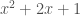 , negative four
, negative four 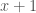 , and seven
, and seven 