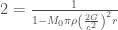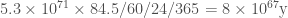On this blog, I write about particle physics for the general public. I try to make things as simple as possible, but I do have to assume some things. In particular, I usually assume you know what particles are!
This time, I won’t do that. I know some people out there don’t know what a particle is, or what particle physicists do. If you’re a person like that, this post is for you! I’m going to give a gentle introduction to what particle physics is all about.
Let’s start with atoms.
Every object and substance around you, everything you can touch or lift or walk on, the water you drink and the air you breathe, all of these are made up of atoms. Some are simple: an iron bar is made of Iron atoms, aluminum foil is mostly Aluminum atoms. Some are made of combinations of atoms into molecules, like water’s famous H2O: each molecule has two Hydrogen atoms and one Oxygen atom. Some are made of more complicated mixtures: air is mostly pairs of Nitrogen atoms, with a healthy amount of pairs of Oxygen, some Carbon Dioxide (CO2), and many other things, while the concrete sidewalks you walk on have Calcium, Silicon, Aluminum, Iron, and Oxygen, all combined in various ways.
There is a dizzying array of different types of atoms, called chemical elements. Most occur in nature, but some are man-made, created by cutting-edge nuclear physics. They can all be organized in the periodic table of elements, which you’ve probably seen on a classroom wall.
The periodic table
The periodic table is called the periodic table because it repeats, periodically. Each element is different, but their properties resemble each other. Oxygen is a gas, Sulfur a yellow powder, Polonium an extremely radioactive metal…but just as you can find H2O, you can make H2S, and even H2Po. The elements get heavier as you go down the table, and more metal-like, but their chemical properties, the kinds of molecules you can make with them, repeat.
Around 1900, physicists started figuring out why the elements repeat. What they discovered is that each atom is made of smaller building-blocks, called sub-atomic particles. (“Sub-atomic” because they’re smaller than atoms!) Each atom has electrons on the outside, and on the inside has a nucleus made of protons and neutrons. Atoms of different elements have different numbers of protons and electrons, which explains their different properties.
Different atoms with different numbers of protons, neutrons, and electrons
Around the same time, other physicists studied electricity, magnetism, and light. These things aren’t made up of atoms, but it was discovered that they are all aspects of the same force, the electromagnetic force. And starting with Einstein, physicists figured out that this force has particles too. A beam of light is made up of another type of sub-atomic particle, called a photon.
For a little while then, it seemed that the universe was beautifully simple. All of matter was made of electrons, protons, and neutrons, while light was made of photons.
(There’s also gravity, of course. That’s more complicated, in this post I’ll leave it out.)
Soon, though, nuclear physicists started noticing stranger things. In the 1930’s, as they tried to understand the physics behind radioactivity and mapped out rays from outer space, they found particles that didn’t fit the recipe. Over the next forty years, theoretical physicists puzzled over their equations, while experimental physicists built machines to slam protons and electrons together, all trying to figure out how they work.
Finally, in the 1970’s, physicists had a theory they thought they could trust. They called this theory the Standard Model. It organized their discoveries, and gave them equations that could predict what future experiments would see.
In the Standard Model, there are two new forces, the weak nuclear force and the strong nuclear force. Just like photons for the electromagnetic force, each of these new forces has a particle. The general word for these particles is bosons, named after Satyendra Nath Bose, a collaborator of Einstein who figured out the right equations for this type of particle. The weak force has bosons called W and Z, while the strong force has bosons called gluons. A final type of boson, called the Higgs boson after a theorist who suggested it, rounds out the picture.
The Standard Model also has new types of matter particles. Neutrinos interact with the weak nuclear force, and are so light and hard to catch that they pass through nearly everything. Quarks are inside protons and neutrons: a proton contains one one down quark and two up quarks, while a neutron contains two down quarks and one up quark. The quarks explained all of the other strange particles found in nuclear physics.
Finally, the Standard Model, like the periodic table, repeats. There are three generations of particles. The first, with electrons, up quarks, down quarks, and one type of neutrino, show up in ordinary matter. The other generations are heavier, and not usually found in nature except in extreme conditions. The second generation has muons (similar to electrons), strange quarks, charm quarks, and a new type of neutrino called a muon-neutrino. The third generation has tauons, bottom quarks, top quarks, and tau-neutrinos.
(You can call these last quarks “truth quarks” and “beauty quarks” instead, if you like.)
Physicists had the equations, but the equations still had some unknowns. They didn’t know how heavy the new particles were, for example. Finding those unknowns took more experiments, over the next forty years. Finally, in 2012, the last unknown was found when a massive machine called the Large Hadron Collider was used to measure the Higgs boson.
The Standard Model
We think that these particles are all elementary particles. Unlike protons and neutrons, which are both made of up quarks and down quarks, we think that the particles of the Standard Model are not made up of anything else, that they really are elementary building-blocks of the universe.
We have the equations, and we’ve found all the unknowns, but there is still more to discover. We haven’t seen everything the Standard Model can do: to see some properties of the particles and check they match, we’d need a new machine, one even bigger than the Large Hadron Collider. We also know that the Standard Model is incomplete. There is at least one new particle, called dark matter, that can’t be any of the known particles. Mysteries involving the neutrinos imply another type of unknown particle. We’re also missing deeper things. There are patterns in the table, like the generations, that we can’t explain.
We don’t know if any one experiment will work, or if any one theory will prove true. So particle physicists keep working, trying to find new tricks and make new discoveries.
A while back I wrote a post trying to reassure you that the Large Hadron Collider cannot create a black hole that could destroy the Earth. If you’re the kind of person who is worried about this kind of thing, you’ve probably heard a variety of arguments: that it hasn’t happened yet, despite the LHC running for quite some time, that it didn’t happen before the LHC with cosmic rays of comparable energy, and that a black hole that small would quickly decay due to Hawking radiation. I thought it would be nice to give a different sort of argument, a back-of-the-envelope calculation you can try out yourself, showing that even if a black hole was produced using all of the LHC’s energy and fell directly into the center of the Earth, and even if Hawking radiation didn’t exist, it would still take longer than the lifetime of the universe to cause any detectable damage. Modeling the black hole as falling through the Earth and just slurping up everything that falls into its event horizon, it wouldn’t even double in size before the stars burn out.
Before the LHC even turned on, the experts were hard at work studying precisely this question. The paper has two authors, Steve Giddings and Michelangelo Mangano. Giddings is an expert on the problem of quantum gravity, while Mangano is an expert on LHC physics, so the two are exactly the dream team you’d ask for to answer this question. Like me, they pretend that black holes don’t decay due to Hawking radiation, and pretend that one falls to straight from the LHC to the center of the Earth, for the most pessimistic possible scenario.
Unlike me, but like my friend, they point out that the Earth is not actually a uniform sphere of matter. It’s made up of particles: quarks arranged into nucleons arranged into nuclei arranged into atoms. And a black hole that hits a nucleus will probably not just slurp up an event horizon-sized chunk of the nucleus: it will slurp up the whole nucleus.
This in turn means that the black hole starts out growing much more fast. Eventually, it slows down again: once it’s bigger than an atom, it starts gobbling up atoms a few at a time until eventually it is back to slurping up a cylinder of the Earth’s material as it passes through.
But an atom-sized black hole will grow faster than an LHC-energy-sized black hole. How much faster is estimated in the Giddings and Mangano paper, and it depends on the number of dimensions. For eight dimensions, we’re safe. For fewer, they need new arguments.
Wait a minute, you might ask, aren’t there only four dimensions? Is this some string theory nonsense?
Kind of, yes. In order for the LHC to produce black holes, gravity would need to have a much stronger effect than we expect on subatomic particles. That requires something weird, and the most plausible such weirdness people considered at the time were extra dimensions. With extra dimensions of the right size, the LHC might have produced black holes. It’s that kind of scenario that Giddings and Mangano are checking: they don’t know of a plausible way for black holes to be produced at the LHC if there are just four dimensions.
For fewer than eight dimensions, though, they have a problem: the back-of-the-envelope calculation suggests black holes could actually grow fast enough to cause real damage. Here, they fall back on the other type of argument: if this could happen, would it have happened already? They argue that, if the LHC could produce black holes in this way, then cosmic rays could produce black holes when they hit super-dense astronomical objects, such as white dwarfs and neutron stars. Those black holes would eat up the white dwarfs and neutron stars, in the same way one might be worried they could eat up the Earth. But we can observe that white dwarfs and neutron stars do in fact exist, and typically live much longer than they would if they were constantly being eaten by miniature black holes. So we can conclude that any black holes like this don’t exist, and we’re safe.
If you’ve got a smattering of physics knowledge, I encourage you to read through the paper. They consider a lot of different scenarios, much more than I can summarize in a post. I don’t know if you’ll find it reassuring, since they may not cover whatever you happen to be worried about. But it’s a lot of fun seeing how the experts handle the problem.
The Higgs boson, or something like it, was pretty much guaranteed.
When physicists turned on the Large Hadron Collider, we didn’t know exactly what they would find. Instead of the Higgs boson, there might have been many strange new particles with different properties. But we knew they had to find something, because without the Higgs boson or a good substitute, the Standard Model is inconsistent. Try to calculate what would happen at the LHC using the Standard Model without the Higgs boson, and you get literal nonsense: chances of particles scattering that are greater than one, a mathematical impossibility. Without the Higgs boson, the Standard Model had to be wrong, and had to go wrong specifically when that machine was turned on. In effect, the LHC was guaranteed to give a Nobel prize.
The LHC also searches for other things, like supersymmetric partner particles. It, and a whole zoo of other experiments, also search for dark matter, narrowing down the possibilities. But unlike the Higgs, none of these searches for dark matter or supersymmetric partners is guaranteed to find something new.
We’re pretty certain that something like dark matter exists, and that it is in some sense “matter”. Galaxies rotate, and masses bend light, in a way that seems only consistent with something new in the universe we didn’t predict. Observations of the whole universe, like the cosmic microwave background, let us estimate the properties of this something new, finding it to behave much more like matter than like radio waves or X-rays. So we call it dark matter.
But none of that guarantees that any of these experiments will find dark matter. The dark matter particles could have many different masses. They might interact faintly with ordinary matter, or with themselves, or almost not at all. They might not technically be particles at all. Each experiment makes some assumption, but no experiment yet can cover the most pessimistic possibility, that dark matter simply doesn’t interact in any usefully detectable way aside from by gravity.
It’s not hard to edit the Standard Model to give neutrinos masses. But there’s more than one way to do it. Every way adds new particles we haven’t yet seen. And none of them tell us what neutrino masses should be. So there are a number of experiments, another zoo, trying to find out. (Maybe this one’s an aquarium?)
Are those experiments guaranteed to work?
Not so much as the LHC was to find the Higgs, but more than the dark matter experiments.
We particle physicists have a kind of holy book, called the Particle Data Book. It summarizes everything we know about every particle, and explains why we know it. It has many pages with many sections, but if you turn to page 10 of this section, you’ll find a small table about neutrinos. The table gives a limit: the neutrino mass is less than 0.8 eV (a mysterious unit called an electron-volt, about ten-to-the-minus-sixteen grams). That limit comes from careful experiments, using E=mc^2 to find what the missing mass could be when an electron-neutrino shoots out in radioactive beta decay. The limit is an inequality, “less than” rather than “equal to”, because the experiments haven’t detected any missing mass yet. So far, they only can tell us what they haven’t seen.
As these experiments get more precise, you could imagine them getting close enough to see some missing mass, and find the mass of a neutrino. And this would be great, and a guaranteed discovery, except that the neutrino they’re measuring isn’t guaranteed to have a mass at all.
We know the neutrino types have different masses, because they oscillate as they travel between the types. But one of the types might have zero mass, and it could well be the electron-neutrino. If it does, then careful experiments on electron-neutrinos may never give us a mass.
Still, there’s a better guarantee than for dark matter. That’s because we can do other experiments, to test the other types of neutrino. These experiments are harder to do, and the bounds they get are less precise. But if the electron neutrino really is massless, then we could imagine getting better and better at these different experiments, until one of them measures something, detecting some missing mass.
(Cosmology helps too. Wiggles in the shape of the universe gives us an estimate of the total, the mass of all the neutrinos averaged together. Currently, it gives another upper bound, but it could give a lower bound as well, which could be used along with weaker versions of the other experiments to find the answer.)
So neutrinos aren’t quite the guarantee the Higgs was, but they’re close. As the experiments get better, key questions will start to be answerable. And another piece of beyond-the-standard-model physics will be understood.
I’m back from CERN this week, with a bit more time to write, so I thought I’d share some thoughts about last week’s Amplitudes conference.
One thing I got wrong in last week’s post: I’ve now been told only 213 people actually showed up in person, as opposed to the 250-ish estimate I had last week. This may seem fewer than Amplitudes in Prague had, but it seems likely they had a few fewer show up than appeared on the website. Overall, the field is at least holding steady from year to year, and definitely has grown since the pandemic (when 2019’s 175 was already a very big attendance).
It was cool having a conference in CERN proper, surrounded by the history of European particle physics. The lecture hall had an abstract particle collision carved into the wood, and the visitor center would in principle have had Standard Model coffee mugs were they not sold out until next May. (There was still enough other particle physics swag, Swiss chocolate, and Swiss chocolate that was also particle physics swag.) I’d planned to stay on-site at the CERN hostel, but I ended up appreciated not doing that: the folks who did seemed to end up a bit cooped up by the end of the conference, even with the conference dinner as a chance to get out.
Past Amplitudes conferences have had associated public lectures. This time we had a not-supposed-to-be-public lecture, a discussion between Nima Arkani-Hamed and Beate Heinemann about the future of particle physics. Nima, prominent as an amplitudeologist, also has a long track record of reasoning about what might lie beyond the Standard Model. Beate Heinemann is an experimentalist, one who has risen through the ranks of a variety of different particle physics experiments, ending up well-positioned to take a broad view of all of them.
It would have been fun if the discussion erupted into an argument, but despite some attempts at provocative questions from the audience that was not going to happen, as Beate and Nima have been friends for a long time. Instead, they exchanged perspectives: on what’s coming up experimentally, and what theories could explain it. Both argued that it was best to have many different directions, a variety of experiments covering a variety of approaches. (There wasn’t any evangelism for particular experiments, besides a joking sotto voce mention of a muon collider.) Nima in particular advocated that, whether theorist or experimentalist, you have to have some belief that what you’re doing could lead to a huge breakthrough. If you think of yourself as just a “foot soldier”, covering one set of checks among many, then you’ll lose motivation. I think Nima would agree that this optimism is irrational, but necessary, sort of like how one hears (maybe inaccurately) that most new businesses fail, but someone still needs to start businesses.
Michelangelo Mangano’s talk on Thursday covered similar ground, but with different emphasis. He agrees that there are still things out there worth discovering: that our current model of the Higgs, for instance, is in some ways just a guess: a simplest-possible answer that doesn’t explain as much as we’d like. But he also emphasized that Standard Model physics can be “new physics” too. Just because we know the model doesn’t mean we can calculate its consequences, and there are a wealth of results from the LHC that improve our models of protons, nuclei, and the types of physical situations they partake in, without changing the Standard Model.
We saw an impressive example of this in Gregory Korchemsky’s talk on Wednesday. He presented an experimental mystery, an odd behavior in the correlation of energies of jets of particles at the LHC. These jets can include a very large number of particles, enough to make it very hard to understand them from first principles. Instead, Korchemsky tried out our field’s favorite toy model, where such calculations are easier. By modeling the situation in the limit of a very large number of particles, he was able to reproduce the behavior of the experiment. The result was a reminder of what particle physics was like before the Standard Model, and what it might become again: partial models to explain odd observations, a quest to use the tools of physics to understand things we can’t just a priori compute.
On the other hand, amplitudes does do a priori computations pretty well as well. Fabrizio Caola’s talk opened the conference by reminding us just how much our precise calculations can do. He pointed out that the LHC has only gathered 5% of its planned data, and already it is able to rule out certain types of new physics to fairly high energies (by ruling out indirect effects, that would show up in high-precision calculations). One of those precise calculations featured in the next talk, by Guilio Gambuti. (A FORM user, his diagrams were the basis for the header image of my Quanta article last winter.) Tiziano Peraro followed up with a technique meant to speed up these kinds of calculations, a trick to simplify one of the more computationally intensive steps in intersection theory.
The rest of Monday was more mathematical, with talks by Zeno Capatti, Jaroslav Trnka, Chia-Kai Kuo, Anastasia Volovich, Francis Brown, Michael Borinsky, and Anna-Laura Sattelberger. Borinksy’s talk felt the most practical, a refinement of his numerical methods complete with some actual claims about computational efficiency. Francis Brown discussed an impressively powerful result, a set of formulas that manages to unite a variety of invariants of Feynman diagrams under a shared explanation.
Tuesday began with what I might call “visitors”: people from adjacent fields with an interest in amplitudes. Alday described how the duality between string theory in AdS space and super Yang-Mills on the boundary can be used to get quite concrete information about string theory, calculating how the theory’s amplitudes are corrected by the curvature of AdS space using a kind of “bootstrap” method that felt nicely familiar. Tim Cohen talked about a kind of geometric picture of theories that extend the Standard Model, including an interesting discussion of whether it’s really “geometric”. Marko Simonovic explained how the integration techniques we develop in scattering amplitudes can also be relevant in cosmology, especially for the next generation of “sky mappers” like the Euclid telescope. This talk was especially interesting to me since this sort of cosmology has a significant presence at CEA Paris-Saclay. Along those lines an interesting paper, “Cosmology meets cohomology”, showed up during the conference. I haven’t had a chance to read it yet!
Just before lunch, we had David Broadhurst give one of his inimitable talks, complete with number theory, extremely precise numerics, and literary and historical references (apparently, Källén died flying his own plane). He also remedied a gap in our whimsically biological diagram naming conventions, renaming the pedestrian “double-box” as a (in this context, Orwellian) lobster. Karol Kampf described unusual structures in a particular Effective Field Theory, while Henriette Elvang’s talk addressed what would become a meaningful subtheme of the conference, where methods from the mathematical field of optimization help amplitudes researchers constrain the space of possible theories. Giulia Isabella covered another topic on this theme later in the day, though one of her group’s selling points is managing to avoid quite so heavy-duty computations.
The other three talks on Tuesday dealt with amplitudes techniques for gravitational wave calculations, as did the first talk on Wednesday. Several of the calculations only dealt with scattering black holes, instead of colliding ones. While some of the results can be used indirectly to understand the colliding case too, a method to directly calculate behavior of colliding black holes came up again and again as an important missing piece.
The talks on Wednesday had to start late, owing to a rather bizarre power outage (the lights in the room worked fine, but not the projector). Since Wednesday was the free afternoon (home of quickly sold-out CERN tours), this meant there were only three talks: Veneziano’s talk on gravitational scattering, Korchemsky’s talk, and Nima’s talk. Nima famously never finishes on time, and this time attempted to control his timing via the surprising method of presenting, rather than one topic, five “abstracts” on recent work that he had not yet published. Even more surprisingly, this almost worked, and he didn’t run too ridiculously over time, while still managing to hint at a variety of ways that the combinatorial lessons behind the amplituhedron are gradually yielding useful perspectives on more general realistic theories.
Thursday, Andrea Puhm began with a survey of celestial amplitudes, a topic that tries to build the same sort of powerful duality used in AdS/CFT but for flat space instead. They’re gradually tackling the weird, sort-of-theory they find on the boundary of flat space. The two next talks, by Lorenz Eberhardt and Hofie Hannesdottir, shared a collaborator in common, namely Sebastian Mizera. They also shared a common theme, taking a problem most people would have assumed was solved and showing that approaching it carefully reveals extensive structure and new insights.
Cristian Vergu, in turn, delved deep into the literature to build up a novel and unusual integration method. We’ve chatted quite a bit about it at the Niels Bohr Institute, so it was nice to see it get some attention on the big stage. We then had an afternoon of trips beyond polylogarithms, with talks by Anne Spiering, Christoph Nega, and Martijn Hidding, each pushing the boundaries of what we can do with our hardest-to-understand integrals. Einan Gardi and Ruth Britto finished the day, with a deeper understanding of the behavior of high-energy particles and a new more mathematically compatible way of thinking about “cut” diagrams, respectively.
On Friday, João Penedones gave us an update on a technique with some links to the effective field theory-optimization ideas that came up earlier, one that “bootstraps” whole non-perturbative amplitudes. Shota Komatsu talked about an intriguing variant of the “planar” limit, one involving large numbers of particles and a slick re-writing of infinite sums of Feynman diagrams. Grant Remmen and Cliff Cheung gave a two-parter on a bewildering variety of things that are both surprisingly like, and surprisingly unlike, string theory: important progress towards answering the question “is string theory unique?”
Friday afternoon brought the last three talks of the conference. James Drummond had more progress trying to understand the symbol letters of supersymmetric Yang-Mills, while Callum Jones showed how Feynman diagrams can apply to yet another unfamiliar field, the study of vortices and their dynamics. Lance Dixon closed the conference without any Greta Thunberg references, but with a result that explains last year’s mystery of antipodal duality. The explanation involves an even more mysterious property called antipodal self-duality, so we’re not out of work yet!
Somewhat overshadowed by the very picturesque Alps
Amplitudes keeps on growing. In 2019, we had 175 participants. We were on Zoom in 2020 and 2021, with many more participants, but that probably shouldn’t count. In Prague last year we had 222. This year, I’ve been told we have even more, something like 250 participants (the list online is bigger, but includes people joining on Zoom). We’ve grown due to new students, but also new collaborations: people from adjacent fields who find the work interesting enough to join along. This year we have mathematicians talking about D-modules, bootstrappers finding new ways to get at amplitudes in string theory, beyond-the-standard-model theorists talking about effective field theories, and cosmologists talking about the large-scale structure of the universe.
The talks have been great, from clear discussions of earlier results to fresh-off-the-presses developments, plenty of work in progress, and even one talk where the speaker’s opinion changed during the coffee break. As we’re at CERN, there’s also a through-line about the future of particle physics, with a chat between Nima Arkani-Hamed and the experimentalist Beate Heinemann on Tuesday and a talk by Michelangelo Mangano about the meaning of “new physics” on Thursday.
I haven’t had a ton of time to write, I keep getting distracted by good discussions! As such, I’ll do my usual thing, and say a bit more about specific talks in next week’s post.
Nowadays, we have telescopes that detect not just light, but gravitational waves. We’ve already learned quite a bit about astrophysics from these telescopes. They observe ripples coming from colliding black holes, giving us a better idea of what kinds of black holes exist in the universe. But the coolest thing a gravitational wave telescope could discover is something that hasn’t been seen yet: a cosmic string.
This art is from an article in Symmetry magazine which is, as far as I can tell, not actually about cosmic strings.
You might have heard of cosmic strings, but unless you’re a physicist you probably don’t know much about them. They’re a prediction, coming from cosmology, of giant string-like objects floating out in space.
That might sound like it has something to do with string theory, but it doesn’t actually have to, you can have these things without any string theory at all. Instead, you might have heard that cosmic strings are some kind of “cracks” or “wrinkles” in space-time. Some articles describe this as like what happens when ice freezes, cracks forming as water settles into a crystal.
That description, in terms of ice forming cracks between crystals, is great…if you’re a physicist who already knows how ice forms cracks between crystals. If you’re not, I’m guessing reading those kinds of explanations isn’t helpful. I’m guessing you’re still wondering why there ought to be any giant strings floating in space.
The real explanation has to do with a type of mathematical gadget physicists use, called a scalar field. You can think of a scalar field as described by a number, like a temperature, that can vary in space and time. The field carries potential energy, and that energy depends on what the scalar field’s “number” is. Left alone, the field settles into a situation with as little potential energy as it can, like a ball rolling down a hill. That situation is one of the field’s default values, something we call a “vacuum” value. Changing the field away from its vacuum value can take a lot of energy. The Higgs boson is one example of a scalar field. Its vacuum value is the value it has in day to day life. In order to make a detectable Higgs boson at the Large Hadron Collider, they needed to change the field away from its vacuum value, and that took a lot of energy.
In the very early universe, almost back at the Big Bang, the world was famously in a hot dense state. That hot dense state meant that there was a lot of energy to go around, so scalar fields could vary far from their vacuum values, pretty much randomly. As the universe expanded and cooled, there was less and less energy available for these fields, and they started to settle down.
Now, the thing about these default, “vacuum” values of a scalar field is that there doesn’t have to be just one of them. Depending on what kind of mathematical function the field’s potential energy is, there could be several different possibilities each with equal energy.
Let’s imagine a simple example, of a field with two vacuum values: +1 and -1. As the universe cooled down, some parts of the universe would end up with that scalar field number equal to +1, and some to -1. But what happens in between?
The scalar field can’t just jump from -1 to +1, that’s not allowed in physics. It has to pass through 0 in between. But, unlike -1 and +1, 0 is not a vacuum value. When the scalar field number is equal to 0, the field has more energy than it does when it’s equal to -1 or +1. Usually, a lot more energy.
That means the region of scalar field number 0 can’t spread very far: the further it spreads, the more energy it takes to keep it that way. On the other hand, the region can’t vanish altogether: something needs to happen to transition between the numbers -1 and +1.
The thing that happens is called a domain wall. A domain wall is a thin sheet, as thin as it can physically be, where the scalar field doesn’t take its vacuum value. You can roughly think of it as made up of the scalar field, a churning zone of the kind of bosons the LHC was trying to detect.
This sheet still has a lot of energy, bound up in the unusual value of the scalar field, like an LHC collision in every proton-sized chunk. As such, like any object with a lot of energy, it has a gravitational field. For a domain wall, the effect of this gravity would be very very dramatic: so dramatic, that we’re pretty sure they’re incredibly rare. If they were at all common, we would have seen evidence of them long before now!
Ok, I’ve shown you a wall, that’s weird, sure. What does that have to do with cosmic strings?
The number representing a scalar field doesn’t have to be a real number: it can be imaginary instead, or even complex. Now I’d like you to imagine a field with vacuum values on the unit circle, in the complex plane. That means that +1 and -1 are still vacuum values, but so are , and , and everything else you can write as . However, 0 is still not a vacuum value. Neither is, for example, .
With vacuum values like this, you can’t form domain walls. You can make a path between -1 and +1 that only goes through the unit circle, through for example. The field will be at its vacuum value throughout, taking no extra energy.
However, imagine the different regions form a circle. In the picture above, suppose that the blue area at the bottom is at vacuum value -1 and red is at +1. You might have in the green region, and in the purple region, covering the whole circle smoothly as you go around.
Now, think about what happens in the middle of the circle. On one side of the circle, you have -1. On the other, +1. (Or, on one side , on the other, ). No matter what, different sides of the circle are not allowed to be next to each other, you can’t just jump between them. So in the very middle of the circle, something else has to happen.
Once again, that something else is a field that goes away from its vacuum value, that passes through 0. Once again, that takes a lot of energy, so it occupies as little space as possible. But now, that space isn’t a giant wall. Instead, it’s a squiggly line: a cosmic string.
Cosmic strings don’t have as dramatic a gravitational effect as domain walls. That means they might not be super-rare. There might be some we haven’t seen yet. And if we do see them, it could be because they wiggle space and time, making gravitational waves.
Cosmic strings don’t require string theory, they come from a much more basic gadget, scalar fields. We know there is one quite important scalar field, the Higgs field. The Higgs vacuum values aren’t like +1 and -1, or like the unit circle, though, so the Higgs by itself won’t make domain walls or cosmic strings. But there are a lot of proposals for scalar fields, things we haven’t discovered but that physicists think might answer lingering questions in particle physics, and some of those could have the right kind of vacuum values to give us cosmic strings. Thus, if we manage to detect cosmic strings, we could learn something about one of those lingering questions.
So, would you believe I’ve never visited CERN before?
I was at CERN for a few days this week, visiting friends and collaborators and giving an impromptu talk. Surprisingly, this is the first time I’ve been, a bit of an embarrassing admission for someone who’s ostensibly a particle physicist.
Despite that, CERN felt oddly familiar. The maze of industrial buildings and winding roads, the security gates and cards (and work-arounds for when you arrive outside of card-issuing hours, assisted by friendly security guards), the constant construction and remodeling, all of it reminded me of the times I visited SLAC during my PhD. This makes a lot of sense, of course: one accelerator is at least somewhat like another. But besides a visit to Fermilab for a conference several years ago, I haven’t been in many other places like that since then.
(One thing that might have also been true of SLAC and Fermilab but I never noticed: CERN buildings not only have evacuation instructions for the building in case of a fire, but also evacuation instructions for the whole site.)
CERN is a bit less “pretty” than SLAC on average, without the nice grassy area in the middle or the California sun that goes with it. It makes up for it with what seems like more in terms of outreach resources, including a big wooden dome of a mini-museum sponsored by Rolex, and a larger visitor center still under construction.
The outside, including a sculpture depicting the history of science with the Higgs boson discovery on the “cutting edge”
The inside. Bubbles on the ground contain either touchscreens or small objects (detectors, papers, a blackboard with the string theory genus expansion for some reason). Bubbles in the air were too high for me to check.
CERN hosts a variety of theoretical physicists doing various different types of work. I was hosted by the “QCD group”, but the string theorists just down the hall include a few people I know as well. The lounge had a few cardboard signs hidden under the table, leftovers of CERN’s famous yearly Christmas play directed by John Ellis.
It’s been a fun, if brief, visit. I’ll likely get to see a bit more this summer, when they host Amplitudes 2023. Until then, it was fun reconnecting with that “accelerator feel”.
I’ve had this conversation a few times over the years. Usually, the people I’m talking to are worried about black holes. They’ve heard that the Large Hadron Collider speeds up particles to amazingly high energies before colliding them together. They worry that these colliding particles could form a black hole, which would fall into the center of the Earth and busily gobble up the whole planet.
This pretty clearly hasn’t happened. But also, physicists were pretty confident that it couldn’t happen. That isn’t to say they thought it was impossible to make a black hole with the LHC. Some physicists actually hoped to make a black hole: it would have been evidence for extra dimensions, curled-up dimensions much larger than the tiny ones required by string theory. They figured out the kind of evidence they’d see if the LHC did indeed create a black hole, and we haven’t seen that evidence. But even before running the machine, they were confident that such a black hole wouldn’t gobble up the planet. Why?
The best argument is also the most unsatisfying. The LHC speeds up particles to high energies, but not unprecedentedly high energies. High-energy particles called cosmic rays enter the atmosphere every day, some of which are at energies comparable to the LHC. The LHC just puts the high-energy particles in front of a bunch of sophisticated equipment so we can measure everything about them. If the LHC could destroy the world, cosmic rays would have already done so.
That’s a very solid argument, but it doesn’t really explain why. Also, it may not be true for future colliders: we could build a collider with enough energy that cosmic rays don’t commonly meet it. So I should give another argument.
The next argument is Hawking radiation. In Stephen Hawking’s most famous accomplishment, he argued that because of quantum mechanics black holes are not truly black. Instead, they give off a constant radiation of every type of particle mixed together, shrinking as it does so. The radiation is faintest for large black holes, but gets more and more intense the smaller the black hole is, until the smallest black holes explode into a shower of particles and disappear. This argument means that a black hole small enough that the LHC could produce it would radiate away to nothing in almost an instant: not long enough to leave the machine, let alone fall to the center of the Earth.
This is a good argument, but maybe you aren’t as sure as I am about Hawking radiation. As it turns out, we’ve never measured Hawking radiation, it’s just a theoretical expectation. Remember that the radiation gets fainter the larger the black hole is: for a black hole in space with the mass of a star, the radiation is so tiny it would be almost impossible to detect even right next to the black hole. From here, in our telescopes, we have no chance of seeing it.
So suppose tiny black holes didn’t radiate, and suppose the LHC could indeed produce them. Wouldn’t that have been dangerous?
Here, we can do a calculation. I want you to appreciate how tiny these black holes would be.
From science fiction and cartoons, you might think of a black hole as a kind of vacuum cleaner, sucking up everything nearby. That’s not how black holes work, though. The “sucking” black holes do is due to gravity, no stronger than the gravity of any other object with the same mass at the same distance. The only difference comes when you get close to the event horizon, an invisible sphere close-in around the black hole. Pass that line, and the gravity is strong enough that you will never escape.
We know how to calculate the position of the event horizon of a black hole. It’s the Schwarzchild radius, and we can write it in terms of Newton’s constant G, the mass of the black hole M, and the speed of light c, as follows:
The Large Hadron Collider’s two beams each have an energy around seven tera-electron-volts, or TeV, so there are 14 TeV of energy in total in each collision. Imagine all of that energy being converted into mass, and that mass forming a black hole. That isn’t how it would actually happen: some of the energy would create other particles, and some would give the black hole a “kick”, some momentum in one direction or another. But we’re going to imagine a “worst-case” scenario, so let’s assume all the energy goes to form the black hole. Electron-volts are a weird physicist unit, but if we divide them by the speed of light squared (as we should if we’re using to create a mass), then Wikipedia tells us that each electron-volt will give us kilograms. “Tera” is the SI prefix for . Thus our tiny black hole starts with a mass of
Plugging in Newton’s constant ( meters cubed per kilogram per second squared), and the speed of light ( meters per second), and we get a radius of,
That, by the way, is amazingly tiny. The size of an atom is about meters. If every atom was a tiny person, and each of that person’s atoms was itself a person, and so on for five levels down, then the atoms of the smallest person would be the same size as this event horizon.
Now, we let this little tiny black hole fall. Let’s imagine it falls directly towards the center of the Earth. The only force affecting it would be gravity (if it had an electrical charge, it would quickly attract a few electrons and become neutral). That means you can think of it as if it were falling through a tiny hole, with no friction, gobbling up anything unfortunate enough to fall within its event horizon.
For our first estimate, we’ll treat the black hole as if it stays the same size through its journey. Imagine the black hole travels through the entire earth, absorbing a cylinder of matter. Using the Earth’s average density of 5515 kilograms per cubic meter, and the Earth’s maximum radius of 6378 kilometers, our cylinder adds a mass of,
That’s absurdly tiny. That’s much, much, much tinier than the mass we started out with. Absorbing an entire cylinder through the Earth makes barely any difference.
You might object, though, that the black hole is gaining mass as it goes. So really we ought to use a differential equation. If the black hole travels a distance r, absorbing mass as it goes at average Earth density , then we find,
Solving this, we get
Where is the mass we start out with.
Plug in the distance through the Earth for r, and we find…still about ! It didn’t change very much, which makes sense, it’s a very very small difference!
So let’s ask a question: how long would it take for a black hole, oscillating like this, to double its mass?
We want to solve,
so we need the black hole to travel a total distance of
That’s a huge distance! The Earth’s radius, remember, is 6378 kilometers. So traveling that far would take
Ten to the sixty-seven years. Our universe is only about ten to the ten years old. In another five times ten to the nine years, the Sun will enter its red giant phase, and swallow the Earth. There simply isn’t enough time for this tiny tiny black hole to gobble up the world, before everything is already gobbled up by something else. Even in the most pessimistic way to walk through the calculation, it’s just not dangerous.
I hope that, if you were worried about black holes at the LHC, you’re not worried any more. But more than that, I hope you’ve learned three lessons. First, that even the highest-energy particle physics involves tiny energies compared to day-to-day experience. Second, that gravitational effects are tiny in the context of particle physics. And third, that with Wikipedia access, you too can answer questions like this. If you’re worried, you can make an estimate, and check!
There’s a saying in physics, attributed to the famous genius John von Neumann: “With four parameters I can fit an elephant, and with five I can make him wiggle his trunk.”
Say you want to model something, like some surprising data from a particle collider. You start with some free parameters: numbers in your model that aren’t decided yet. You then decide those numbers, “fixing” them based on the data you want to model. Your goal is for your model not only to match the data, but to predict something you haven’t yet measured. Then you can go out and check, and see if your model works.
The more free parameters you have in your model, the easier this can go wrong. More free parameters make it easier to fit your data, but that’s because they make it easier to fit any data. Your model ends up not just matching the physics, but matching the mistakes as well: the small errors that crop up in any experiment. A model like that may look like it’s a great fit to the data, but its predictions will almost all be wrong. It wasn’t just fit, it was overfit.
We have statistical tools that tell us when to worry about overfitting, when we should be impressed by a model and when it has too many parameters. We don’t actually use these tools correctly, but they still give us a hint of what we actually want to know, namely, whether our model will make the right predictions. In a sense, these tools form the mathematical basis for Occam’s Razor, the idea that the best explanation is often the simplest one, and Occam’s Razor is a critical part of how we do science.
So, did you know machine learning was just modeling data?
All of the much-hyped recent advances in artificial intelligence, GPT and Stable Diffusion and all those folks, at heart they’re all doing this kind of thing. They start out with a model (with a lot more than five parameters, arranged in complicated layers…), then use data to fix the free parameters. Unlike most of the models physicists use, they can’t perfectly fix these numbers: there are too many of them, so they have to approximate. They then test their model on new data, and hope it still works.
Increasingly, it does, and impressively well, so well that the average person probably doesn’t realize this is what it’s doing. When you ask one of these AIs to make an image for you, what you’re doing is asking what image the model predicts would show up captioned with your text. It’s the same sort of thing as asking an economist what their model predicts the unemployment rate will be when inflation goes up. The machine learning model is just way, way more complicated.
As a physicist, the first time I heard about this, I had von Neumann’s quote in the back of my head. Yes, these machines are dealing with a lot more data, from a much more complicated reality. They literally are trying to fit elephants, even elephants wiggling their trunks. Still, the sheer number of parameters seemed fishy here. And for a little bit things seemed even more fishy, when I learned about double descent.
Suppose you start increasing the number of parameters in your model. Initially, your model gets better and better. Your predictions have less and less error, your error descends. Eventually, though, the error increases again: you have too many parameters so you’re over-fitting, and your model is capturing accidents in your data, not reality.
In machine learning, weirdly, this is often not the end of the story. Sometimes, your prediction error rises, only to fall once more, in a double descent.
For a while, I found this deeply disturbing. The idea that you can fit your data, start overfitting, and then keep overfitting, and somehow end up safe in the end, was terrifying. The way some of the popular accounts described it, like you were just overfitting more and more and that was fine, was baffling, especially when they seemed to predict that you could keep adding parameters, keep fitting tinier and tinier fleas on the elephant’s trunk, and your predictions would never start going wrong. It would be the death of Occam’s Razor as we know it, more complicated explanations beating simpler ones off to infinity.
Luckily, that’s not what happens. And after talking to a bunch of people, I think I finally understand this enough to say something about it here.
The right way to think about double descent is as overfitting prematurely. You do still expect your error to eventually go up: your model won’t be perfect forever, at some point you will really overfit. It might take a long time, though: machine learning people are trying to model very complicated things, like human behavior, with giant piles of data, so very complicated models may often be entirely appropriate. In the meantime, due to a bad choice of model, you can accidentally overfit early. You will eventually overcome this, pushing past with more parameters into a model that works again, but for a little while you might convince yourself, wrongly, that you have nothing more to learn.
So Occam’s Razor still holds, but with a twist. The best model is simple enough, but no simpler. And if you’re not careful enough, you can convince yourself that a too-simple model is as complicated as you can get.
Image from Astral Codex Ten
I was reminded of all this recently by somearticles by Sabine Hossenfelder.
Hossenfelder is a critic of mainstream fundamental physics. The articles were her restating a point she’s made many times before, including in (at least) one of her books. She thinks the people who propose new particles and try to search for them are wasting time, and the experiments motivated by those particles are wasting money. She’s motivated by something like Occam’s Razor, the need to stick to the simplest possible model that fits the evidence. In her view, the simplest models are those in which we don’t detect any more new particles any time soon, so those are the models she thinks we should stick with.
I tend to disagree with Hossenfelder. Here, I was oddly conflicted. In some of her examples, it seemed like she had a legitimate point. Others seemed like she missed the mark entirely.
Talk to most astrophysicists, and they’ll tell you dark matter is settled science. Indeed, there is a huge amount of evidence that something exists out there in the universe that we can’t see. It distorts the way galaxies rotate, lenses light with its gravity, and wiggled the early universe in pretty much the way you’d expect matter to.
What isn’t settled is whether that “something” interacts with anything else. It has to interact with gravity, of course, but everything else is in some sense “optional”. Astroparticle physicists use satellites to search for clues that dark matter has some other interactions: perhaps it is unstable, sometimes releasing tiny signals of light. If it did, it might solve other problems as well.
Hossenfelder thinks this is bunk (in part because she thinks those other problems are bunk). I kind of do too, though perhaps for a more general reason: I don’t think nature owes us an easy explanation. Dark matter isn’t obligated to solve any of our other problems, it just has to be dark matter. That seems in some sense like the simplest explanation, the one demanded by Occam’s Razor.
At the same time, I disagree with her substantially more on collider physics. At the Large Hadron Collider so far, all of the data is reasonably compatible with the Standard Model, our roughly half-century old theory of particle physics. Collider physicists search that data for subtle deviations, one of which might point to a general discrepancy, a hint of something beyond the Standard Model.
While my intuitions say that the simplest dark matter is completely dark, they don’t say that the simplest particle physics is the Standard Model. Back when the Standard Model was proposed, people might have said it was exceptionally simple because it had a property called “renormalizability”, but these days we view that as less important. Physicists like Ken Wilson and Steven Weinberg taught us to view theories as a kind of series of corrections, like a Taylor series in calculus. Each correction encodes new, rarer ways that particles can interact. A renormalizable theory is just the first term in this series. The higher terms might be zero, but they might not. We even know that some terms cannot be zero, because gravity is not renormalizable.
The two cases on the surface don’t seem that different. Dark matter might have zero interactions besides gravity, but it might have other interactions. The Standard Model might have zero corrections, but it might have nonzero corrections. But for some reason, my intuition treats the two differently: I would find it completely reasonable for dark matter to have no extra interactions, but very strange for the Standard Model to have no corrections.
I think part of where my intuition comes from here is my experience with other theories.
One example is a toy model called sine-Gordon theory. In sine-Gordon theory, this Taylor series of corrections is a very familiar Taylor series: the sine function! If you go correction by correction, you’ll see new interactions and more new interactions. But if you actually add them all up, something surprising happens. Sine-Gordon turns out to be a special theory, one with “no particle production”: unlike in normal particle physics, in sine-Gordon particles can neither be created nor destroyed. You would never know this if you did not add up all of the corrections.
String theory itself is another example. In string theory, elementary particles are replaced by strings, but you can think of that stringy behavior as a series of corrections on top of ordinary particles. Once again, you can try adding these things up correction by correction, but once again the “magic” doesn’t happen until the end. Only in the full series does string theory “do its thing”, and fix some of the big problems of quantum gravity.
If the real world really is a theory like this, then I think we have to worry about something like double descent.
Remember, double descent happens when our models can prematurely get worse before getting better. This can happen if the real thing we’re trying to model is very different from the model we’re using, like the example in this explainer that tries to use straight lines to match a curve. If we think a model is simpler because it puts fewer corrections on top of the Standard Model, then we may end up rejecting a reality with infinite corrections, a Taylor series that happens to add up to something quite nice. Occam’s Razor stops helping us if we can’t tell which models are really the simple ones.
The problem here is that every notion of “simple” we can appeal to here is aesthetic, a choice based on what makes the math look nicer. Other sciences don’t have this problem. When a biologist or a chemist wants to look for the simplest model, they look for a model with fewer organisms, fewer reactions…in the end, fewer atoms and molecules, fewer of the building-blocks given to those fields by physics. Fundamental physics can’t do this: we build our theories up from mathematics, and mathematics only demands that we be consistent. We can call theories simpler because we can write them in a simple way (but we could write them in a different way too). Or we can call them simpler because they look more like toy models we’ve worked with before (but those toy models are just a tiny sample of all the theories that are possible). We don’t have a standard of simplicity that is actually reliable.
From the Wikipedia page for dark matter halos
There is one other way out of this pickle. A theory that is easier to write down is under no obligation to be true. But it is more likely to be useful. Even if the real world is ultimately described by some giant pile of mathematical parameters, if a simple theory is good enough for the engineers then it’s a better theory to aim for: a useful theory that makes peoples’ lives better.
I kind of get the feeling Hossenfelder would make this objection. I’ve seen her argue on twitter that scientists should always be able to say what their research is good for, and her Guardian article has this suggestive sentence: “However, we do not know that dark matter is indeed made of particles; and even if it is, to explain astrophysical observations one does not need to know details of the particles’ behaviour.”
Ok yes, to explain astrophysical observations one doesn’t need to know the details of dark matter particles’ behavior. But taking a step back, one doesn’t actually need to explain astrophysical observations at all.
Astrophysics and particle physics are not engineering problems. Nobody out there is trying to steer a spacecraft all the way across a galaxy, navigating the distribution of dark matter, or creating new universes and trying to make sure they go just right. Even if we might do these things some day, it will be so far in the future that our attempts to understand them won’t just be quaint: they will likely be actively damaging, confusing old research in dead languages that the field will be better off ignoring to start from scratch.
Because of that, usefulness is also not a meaningful guide. It cannot tell you which theories are more simple, which to favor with Occam’s Razor.
Hossenfelder’s highest-profile recent work falls afoul of one or the other of her principles. Her work on the foundations of quantum mechanics could genuinely be useful, but there’s no reason aside from claims of philosophical beauty to expect it to be true. Her work on modeling dark matter is at least directly motivated by data, but is guaranteed to not be useful.
I’m not pointing this out to call Hossenfelder a hypocrite, as some sort of ad hominem or tu quoque. I’m pointing this out because I don’t think it’s possible to do fundamental physics today without falling afoul of these principles. If you want to hold out hope that your work is useful, you don’t have a great reason besides a love of pretty math: otherwise, anything useful would have been discovered long ago. If you just try to model existing data as best you can, then you’re making a model for events far away or locked in high-energy particle colliders, a model no-one else besides other physicists will ever use.
I don’t know the way through this. I think if you need to take Occam’s Razor seriously, to build on the same foundations that work in every other scientific field…then you should stop doing fundamental physics. You won’t be able to make it work. If you still need to do it, if you can’t give up the sub-field, then you should justify it on building capabilities, on the kind of “practice” Hossenfelder also dismisses in her Guardian piece.
We don’t have a solid foundation, a reliable notion of what is simple and what isn’t. We have guesses and personal opinions. And until some experiment uncovers some blinding flash of new useful meaningful magic…I don’t think we can do any better than that.
I’m back from Amplitudes 2022 with more time to write, and (besides the several papers I’m working on) that means writing about the conference! Casual readers be warned, there’s no way around this being a technical post, I don’t have the space to explain everything!
I mostly said all I wanted about the way the conference was set up in last week’s post, but one thing I didn’t say much about was the conference dinner. Most conference dinners are the same aside from the occasional cool location or haggis speech. This one did have a cool location, and a cool performance by a blind pianist, but the thing I really wanted to comment on was the setup. Typically, the conference dinner at Amplitudes is a sit-down affair: people sit at tables in one big room, maybe getting up occasionally to pick up food, and eventually someone gives an after-dinner speech. This time the tables were standing tables, spread across several rooms. This was a bit tiring on a hot day, but it did have the advantage that it naturally mixed people around. Rather than mostly talking to “your table”, you’d wander, ending up at a new table every time you picked up new food or drinks. It was a good way to meet new people, a surprising number of which in my case apparently read this blog. It did make it harder to do an after-dinner speech, so instead Lance gave an after-conference speech, complete with the now-well-established running joke where Greta Thunberg tries to get us to fly less.
(In another semi-running joke, the organizers tried to figure out who had attended the most of the yearly Amplitudes conferences over the years. Weirdly, no-one has attended all twelve.)
In terms of the content, and things that stood out:
Nima is getting close to publishing his newest ‘hedron, the surfacehedron, and correspondingly was able to give a lot more technical detail about it. (For his first and most famous amplituhedron, see here.) He still didn’t have enough time to explain why he has to use category theory to do it, but at least he was concrete enough that it was reasonably clear where the category theory was showing up. (I wasn’t there for his eight-hour lecture at the school the week before, maybe the students who stuck around until 2am learned some category theory there.) Just from listening in on side discussions, I got the impression that some of the ideas here actually may have near-term applications to computing Feynman diagrams: this hasn’t been a feature of previous ‘hedra and it’s an encouraging development.
Alex Edison talked about progress towards this blog’s namesake problem, the question of whether N=8 supergravity diverges at seven loops. Currently they’re working at six loops on the N=4 super Yang-Mills side, not yet in a form it can be “double-copied” to supergravity. The tools they’re using are increasingly sophisticated, including various slick tricks from algebraic geometry. They are looking to the future: if they’re hoping their methods will reach seven loops, the same methods have to make six loops a breeze.
Xi Yin approached a puzzle with methods from String Field Theory, prompting the heretical-for-us title “on-shell bad, off-shell good”. A colleague reminded me of a local tradition for dealing with heretics.
While Nima was talking about a new ‘hedron, other talks focused on the original amplituhedron. Paul Heslop found that the amplituhedron is not literally a positive geometry, despite slogans to the contrary, but what it is is nonetheless an interesting generalization of the concept. Livia Ferro has made more progress on her group’s momentum amplituhedron: previously only valid at tree level, they now have a picture that can accomodate loops. I wasn’t sure this would be possible, there are a lot of things that work at tree level and not for loops, so I’m quite encouraged that this one made the leap successfully.
Sebastian Mizera, Andrew McLeod, and Hofie Hannesdottir all had talks that could be roughly summarized as “deep principles made surprisingly useful”. Each took topics that were explored in the 60’s and translated them into concrete techniques that could be applied to modern problems. There were surprisingly few talks on the completely concrete end, on direct applications to collider physics. I think Simone Zoia’s was the only one to actually feature collider data with error bars, which might explain why I singled him out to ask about those error bars later.
Likewise, Matthias Wilhelm’s talk was the only one on functions beyond polylogarithms, the elliptic functions I’ve also worked on recently. I wonder if the under-representation of some of these topics is due to the existence of independent conferences: in a year when in-person conferences are packed in after being postponed across the pandemic, when there are already dedicated conferences for elliptics and practical collider calculations, maybe people are just a bit too tired to go to Amplitudes as well.
Talks on gravitational waves seem to have stabilized at roughly a day’s worth, which seems reasonable. While the subfield’s capabilities continue to be impressive, it’s also interesting how often new conceptual challenges appear. It seems like every time a challenge to their results or methods is resolved, a new one shows up. I don’t know whether the field will ever get to a stage of “business as usual”, or whether it will be novel qualitative questions “all the way up”.
I haven’t said much about the variety of talks bounding EFTs and investigating their structure, though this continues to be an important topic. And I haven’t mentioned Lance Dixon’s talk on antipodal duality, largely because I’m planning a post on it later: Quanta Magazine had a good article on it, but there are some aspects even Quanta struggled to cover, and I think I might have a good way to do it.








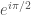 , and
, and 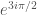 , and everything else you can write as
, and everything else you can write as  . However, 0 is still not a vacuum value. Neither is, for example,
. However, 0 is still not a vacuum value. Neither is, for example,  .
.


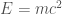 to create a mass), then
to create a mass), then  kilograms. “Tera” is
kilograms. “Tera” is 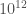 . Thus our tiny black hole starts with a mass of
. Thus our tiny black hole starts with a mass of 
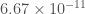 meters cubed per kilogram per second squared), and the speed of light (
meters cubed per kilogram per second squared), and the speed of light (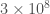 meters per second), and we get a radius of,
meters per second), and we get a radius of,
 meters. If every atom was a tiny person, and each of that person’s atoms was itself a person, and so on for five levels down, then the atoms of the smallest person would be the same size as this event horizon.
meters. If every atom was a tiny person, and each of that person’s atoms was itself a person, and so on for five levels down, then the atoms of the smallest person would be the same size as this event horizon.
 , then we find,
, then we find,

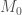 is the mass we start out with.
is the mass we start out with.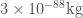 ! It didn’t change very much, which makes sense, it’s a very very small difference!
! It didn’t change very much, which makes sense, it’s a very very small difference!