I’m graduating this week, so I probably shouldn’t spend too much time writing this post. I ought to mention, though, that there has been some doubt about the recent discovery by the BICEP2 telescope of evidence for gravitational waves in the cosmic microwave background caused by the early inflation of the universe. Résonaances got to the story first and Of Particular Significance has some good coverage that should be understandable to a wide audience.
In brief, the worry is that the signal detected by BICEP2 might not be caused by inflation, but instead by interstellar dust. While the BICEP2 team used several models of dust to show that it should be negligible, the controversy centers around one of these models in particular, one taken from another, similar experiment called PLANCK.
The problem is, BICEP2 didn’t get PLANCK’s information on dust directly. Instead, it appears they took the data from a slide in a talk by the PLANCK team. This process, known as “data scraping”, involves taking published copies of the slides and reading information off of the charts presented. If BICEP2 misinterpreted the slide, they might have miscalculated the contribution by interstellar dust.
If you’re like me, the whole idea of data scraping seems completely ludicrous. The idea of professional scientists sneaking information off of a presentation, rather than simply asking the other team for data like reasonable human beings, feels almost cartoonishly wrong-headed.
It’s a bit more understandable, though, when you think about the culture behind these big experiments. The PLANCK and BICEP2 teams are colleagues, but they are also competitors. There is an enormous amount of glory in finding evidence for something like cosmic inflation first, and an equally enormous amount of shame in screwing up and announcing something that turns out to be wrong. As such, these experiments are quite protective of their data. Not only might someone with early access to the data preempt them on an important discovery, they might rush to publish a conclusion that is wrong. That’s why most of these big experiments spend a large amount of time checking and re-checking the data, communicating amongst themselves and settling on an interpretation before they feel comfortable releasing it to the wider community. It’s why BICEP2 couldn’t just ask PLANCK for their data.
From BICEP2’s perspective, they can expect that plots presented at a talk by PLANCK should be accurate, digital plots. Unlike Fox News, scientists have an obligation to present their data in a way that isn’t misleading. And while relying on such a dubious source seems like a bad idea, by all accounts that’s not what the BICEP2 team did. PLANCK’s data was just one dust model used by the team, kept in part because it agreed well with other, non-“data-scraped” models.
It’s a shame that these experiments are so large and prestigious that they need to guard their data in such a potentially destructive way. My sub-field is generally much nicer about this sort of thing: the stakes are lower, and the groups are smaller and have less media attention, so we’re able to share data when we need to. In fact, my most recent paper got a significant boost from some data shared by folks at the Perimeter Institute.
Only time will tell whether the BICEP2 result wins out, or whether it was a fluke caused by caustic data-sharing practices. A number of other experiments are coming online within the next year, and one of them may confirm or deny what BICEP2 has showed.





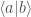 . What if you need to separate the two states,
. What if you need to separate the two states,  and
and 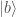 ?
?