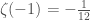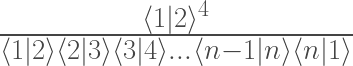I am an Amplitudeologist. In other words, I study scattering amplitudes. I’ve explained bits and pieces of what scattering amplitudes are in other posts, but I ought to give a short definition here so everyone’s on the same page:
A scattering amplitude is the formula used to calculate the probability that some collection of particles will “scatter”, emerging as some (possibly different) collection of particles.
Note that I’m using some weasel words here. The scattering amplitude is not a probability itself, but “the formula used to calculate the probability”. For those familiar with the mathematics of waves, the scattering amplitude gives the amplitude of a “probability wave” that must be squared to get the probability. (Those familiar with waves might also ask: “If this is the amplitude, what about the period?” The truth is that because scattering amplitudes are calculated using complex numbers, what we call the “amplitude” also contains information about the wave’s “period”. It may seem like an inconsistent way to name things from the perspective of a beginning student, but it is actually consistent with the terminology in a large chunk of physics.)
In some of the simplest scattering amplitudes particles literally “scatter”, with two particles “colliding” and emerging traveling in different directions.
A scattering amplitude can also describe a more complicated situation, though. At particle colliders like the Large Hadron Collider, two particles (a pair of protons for the LHC) are accelerated fast enough that when they collide they release a whole slew of new particles. Since it still fits the “some particles go in, some particles go out” template, this is still described by a scattering amplitude.
It goes even further than that, though, because “some particles” could also just be “one particle”. If you’re dealing with something unstable (the particle equivalent of radioactive, essentially) then one particle can decay into two or more particles. There’s a whole slew of questions that require that sort of calculation. For example, if unstable particles were produced in the early universe, how many of them would be left around today? If dark matter is unstable (and some possible candidates are), when it decays it might release particles we could detect. In general, this sort of scattering amplitude is often of interest to astrophysicists when they happen to get involved in particle physics.
You can even use scattering amplitudes to describe situations that, at first glance, don’t sound like collisions of particles at all. If you want to find the effect of a magnetic field on an electron to high accuracy, the calculation also involves a scattering amplitude. A magnetic field can be thought of in terms of photons, particles of light, because light is a vibration in the electro-magnetic field. This means that the effect of a magnetic field on an electron can be calculated by “scattering” an electron and a photon.

If this looks familiar, check the handbook section.
In fact, doing the calculation in this way leads to what is possibly the most accurately predicted number in all of science.
Scattering amplitudes show up all over the place, from particle physics at the Large Hadron Collider to astrophysics to delicate experiments on electrons in magnetic fields. That said, there are plenty of things people calculate in theoretical physics that don’t use scattering amplitudes, either because they involve questions that are difficult to answer from the scattering amplitude point of view, or because they invoke different formulas altogether. Still, scattering amplitudes are central to the work of a large number of physicists. They really do cover just about everything.













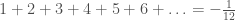
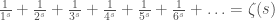
 , the
, the