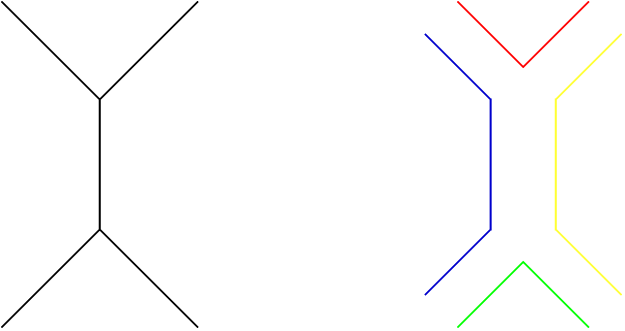
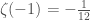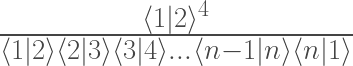My new paper went up last night.
It’s on a very similar topic to my last paper, actually. That paper dealt with a specific process involving six particles in my favorite theory, N=4 super Yang-Mills. Two particles collide, and after the metaphorical dust settles four particles emerge. That means six “total” particles, if you add the two in with the four out, for a “hexagon” of variables. To understand situations like that, my collaborators and I created “hexagon functions”, formulas that depended on the states of the six particles.
One thing I didn’t emphasize then was that that calculation only applied to one specific choice of particles, one in which all of the particles are Yang-Mills bosons, particles (like photons) created by the fundamental forces. There are lots of other particles in N=4 super Yang-Mills, though. What happens when they collide?
That question is answered by my new paper. Though it may sound surprising, all of the other particles can be taken into account with a single formula. In order to explain why, I have to tell you about something called superspace.
A while back I complained about a blog post by George Musser about the (2,0) theory. One of the things that irked me about that post was his attempt to explain superspace:
Supersymmetry is the idea that spacetime, in addition to its usual dimensions of space and time, has an entirely different type of dimension—a quantum dimension, whose coordinates are not ordinary real numbers but a whole new class of number that can be thought of as the square roots of zero.
This is actually a great way to think about superspace…if you’re already a physicist. If you’re not, it’s not very informative. Here’s a better way to think about it:
As I’ve talked about before, supersymmetry is a relationship between different types of particles. Two particles related by supersymmetry have the same mass, and the same charge. While they can be very different in other ways (specifically, having different spin), supersymmetric particles are described by many of the same equations as each-other. Rather than writing out those equations multiple times, it’s often nicer to write them all in a unified way, and that’s where superspace comes in.
At its simplest, superspace is just a trick used to write equations in a simpler way. Instead of writing down a different equation for each particle we write one equation with an extra variable, representing a “dimension” of supersymmetry. Traveling in that dimension takes you from particle to particle, in the same way that “turning” the theory (as I phrase it here) does, but it does it within the space of a single equation.
That, essentially, is the trick that we use. With four “superspace dimensions”, we can include the four supersymmetries of N=4 super Yang-Mills, showing how the formulas vary when you go beyond the equation from our first paper.
So far, you may be wondering why I’m calling superspace a “dimension”, when it probably sounds like more of a label. I’ve mentioned before that, just because something is a variable, doesn’t mean it counts as a real dimension.
The key difference is that superspace dimensions are related to regular dimensions in a precise way. In a sense, they’re the square roots of regular dimensions. (Though independently, as George Musser described, they’re the square roots of zero: go in the same direction twice in supersymmetry, and you get back where you’re started, going zero distance.) The coexistence of these two seemingly contradictory statements isn’t some sort of quantum mystery, it’s just a consequence of the fact that, mathematically, I’m saying two very different things. I just can’t think of a way to explain them differently without math.
Superspace isn’t a real place…but it can often be useful to think of it that way. In theories with supersymmetry, it can unify the world, putting disparate particles together into a single equation.













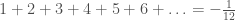
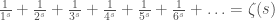
 , the
, the