A few weeks back, Quanta Magazine had an article about a new discovery in my field, called antipodal duality.
Some background: I’m a theoretical physicist, and I work on finding better ways to make predictions in particle physics. Folks in my field make these predictions with formulas called “scattering amplitudes” that encode the probability that particles bounce, or scatter, in particular ways. One trick we’ve found is that these formulas can often be written as “words” in a kind of “alphabet”. If we know the alphabet, we can make our formulas much simpler, or even guess formulas we could never have calculated any other way.
Quanta’s article describes how a few friends of mine (Lance Dixon, Ömer Gürdoğan, Andrew McLeod, and Matthias Wilhelm) noticed a weird pattern in two of these formulas, from two different calculations. If you flip the “words” around, back to front (an operation called the antipode), you go from a formula describing one collision of particles to a formula for totally different particles. Somehow, the two calculations are “dual”: two different-seeming descriptions that secretly mean the same thing.
Quanta quoted me for their article, and I was (pleasantly) baffled. See, the antipode was supposed to be useless. The mathematicians told us it was something the math allows us to do, like you’re allowed to order pineapple on pizza. But just like pineapple on pizza, we couldn’t imagine a situation where we actually wanted to do it.
What Quanta didn’t say was why we thought the antipode was useless. That’s a hard story to tell, one that wouldn’t fit in a piece like that.
It fits here, though. So in the rest of this post, I’d like to explain why flipping around words is such a strange, seemingly useless thing to do. It’s strange because it swaps two things that in physics we thought should be independent: branch cuts and derivatives, or particles and symmetries.
Let’s start with the first things in each pair: branch cuts, and particles.
The first few letters of our “word” tell us something mathematical, and they tell us something physical. Mathematically, they tell us ways that our formula can change suddenly, and discontinuously.
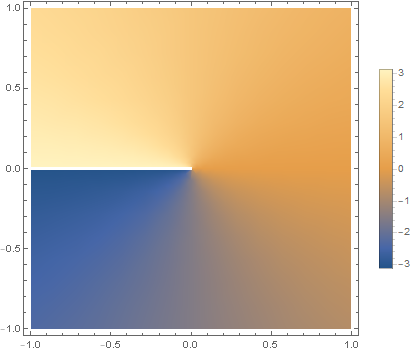
Take a logarithm, the inverse of 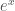 . You’re probably used to plugging in positive numbers, and getting out something reasonable, that changes in a smooth and regular way: after all, is always positive, right? But in mathematics, you don’t have to just use positive numbers. You can use negative numbers. Even more interestingly, you can use complex numbers. And if you take the logarithm of a complex number, and look at the imaginary part, it looks like this:
. You’re probably used to plugging in positive numbers, and getting out something reasonable, that changes in a smooth and regular way: after all, is always positive, right? But in mathematics, you don’t have to just use positive numbers. You can use negative numbers. Even more interestingly, you can use complex numbers. And if you take the logarithm of a complex number, and look at the imaginary part, it looks like this:
Mostly, this complex logarithm still seems to be doing what it’s supposed to, changing in a nice slow way. But there is a weird “cut” in the graph for negative numbers: a sudden jump, from  to
to 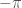 . That jump is called a “branch cut”.
. That jump is called a “branch cut”.
As physicists, we usually don’t like our formulas to make sudden changes. A change like this is an infinitely fast jump, and we don’t like infinities much either. But we do have one good use for a formula like this, because sometimes our formulas do change suddenly: when we have enough energy to make a new particle.
Imagine colliding two protons together, like at the LHC. Colliding particles doesn’t just break the protons into pieces: due to Einstein’s famous 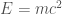 , it can create new particles as well. But to create a new particle, you need enough energy:
, it can create new particles as well. But to create a new particle, you need enough energy:  worth of energy. So as you dial up the energy of your protons, you’ll notice a sudden change: you couldn’t create, say, a Higgs boson, and now you can. Our formulas represent some of those kinds of sudden changes with branch cuts.
worth of energy. So as you dial up the energy of your protons, you’ll notice a sudden change: you couldn’t create, say, a Higgs boson, and now you can. Our formulas represent some of those kinds of sudden changes with branch cuts.
So the beginning of our “words” represent branch cuts, and particles. The end represents derivatives and symmetries.
Derivatives come from the land of calculus, a place spooky to those with traumatic math class memories. Derivatives shouldn’t be so spooky though. They’re just ways we measure change. If we have a formula that is smoothly changing as we change some input, we can describe that change with a derivative.
The ending of our “words” tell us what happens when we take a derivative. They tell us which ways our formulas can smoothly change, and what happens when they do.
In doing so, they tell us about something some physicists make sound spooky, called symmetries. Symmetries are changes we can make that don’t really change what’s important. For example, you could imagine lifting up the entire Large Hadron Collider and (carefully!) carrying it across the ocean, from France to the US. We’d expect that, once all the scared scientists return and turn it back on, it would start getting exactly the same results. Physics has “translation symmetry”: you can move, or “translate” an experiment, and the important stuff stays the same.
These symmetries are closely connected to derivatives. If changing something doesn’t change anything important, that should be reflected in our formulas: they shouldn’t change either, so their derivatives should be zero. If instead the symmetry isn’t quite true, if it’s what we call “broken”, then by knowing how it was “broken” we know what the derivative should be.
So branch cuts tell us about particles, derivatives tell us about symmetries. The weird thing about the antipode, the un-physical bizarre thing, is that it swaps them. It makes the particles of one calculation determine the symmetries of another.
(And lest you’ve heard about particles with symmetries, like gluons and SU(3)…this is a different kind of thing. I don’t have enough room to explain why here, but it’s completely unrelated.)
Why the heck does this duality exist?
A commenter on the last post asked me to speculate. I said there that I have no clue, and that’s most of the answer.
If I had to speculate, though, my answer might be disappointing.
Most of the things in physics we call “dualities” have fairly deep physical meanings, linked to twisting spacetime in complicated ways. AdS/CFT isn’t fully explained, but it seems to be related to something called the holographic principle, the idea that gravity ties together the inside of space with the boundary around it. T duality, an older concept in string theory, is explained: a consequence of how strings “see” the world in terms of things to wrap around and things to spin around. In my field, one of our favorite dualities links back to this as well, amplitude-Wilson loop duality linked to fermionic T-duality.
The antipode doesn’t twist spacetime, it twists the mathematics. And it may be it matters only because the mathematics is so constrained that it’s forced to happen.
The trick that Lance Dixon and co. used to discover antipodal duality is the same trick I used with Lance to calculate complicated scattering amplitudes. It relies on taking a general guess of words in the right “alphabet”, and constraining it: using mathematical and physical principles it must obey and throwing out every illegal answer until there’s only one answer left.
Currently, there are some hints that the principles used for the different calculations linked by antipodal duality are “antipodal mirrors” of each other: that different principles have the same implication when the duality “flips” them around. If so, then it could be this duality is in some sense just a coincidence: not a coincidence limited to a few calculations, but a coincidence limited to a few principles. Thought of in this way, it might not tell us a lot about other situations, it might not really be “deep”.
Of course, I could be wrong about this. It could be much more general, could mean much more. But in that context, I really have no clue what to speculate. The antipode is weird: it links things that really should not be physically linked. We’ll have to see what that actually means.


 , and
, and  . Do some algebra, and you’ll see that for those to cancel, you need
. Do some algebra, and you’ll see that for those to cancel, you need  .
.  . This time you need not just some algebra, but some calculus. I’ll let the students in the audience work it out, but at the end of the day, you should notice how C behaves when
. This time you need not just some algebra, but some calculus. I’ll let the students in the audience work it out, but at the end of the day, you should notice how C behaves when 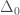 is small. It isn’t like
is small. It isn’t like ![\sqrt[3]{\Delta_0}](https://s0.wp.com/latex.php?latex=%5Csqrt%5B3%5D%7B%5CDelta_0%7D&bg=ffffff&fg=444444&s=0&c=20201002) . It’s like just plain
. It’s like just plain 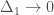 as well. And that’s just fine according to those theorems from the 60’s. So our cubic curiosity isn’t impossible after all.
as well. And that’s just fine according to those theorems from the 60’s. So our cubic curiosity isn’t impossible after all.