Three of my science journalism pieces went up last week!
(This is a total coincidence. One piece was a general explainer “held in reserve” for a nice slot in the schedule, one was a piece I drafted in February, while the third I worked on in May. In journalism, things take as long as they take.)
The shortest piece, at Quanta Magazine, was an explainer about the two types of particles in physics: bosons, and fermions.
I don’t have a ton of bonus info here, because of how tidy the topic is, so just two quick observations.
First, I have the vague impression that Bose, bosons’ namesake, is “claimed” by both modern-day Bangladesh and India. I had friends in grad school who were proud of their fellow physicist from Bangladesh, but while he did his most famous work in Dhaka, he was born and died in Calcutta. Since both were under British India for most of his life, these things likely get complicated.
Second, at the end of the piece I mention a “world on a wire” where fermions and bosons are the same. One example of such a “wire” is a string, like in string theory. One thing all young string theorists learn is “bosonization”: the idea that, in a 1+1-dimensional world like a string, you can re-write any theory with fermions as a theory with bosons, as well as vice versa. This has important implications for how string theory is set up.
Next, in Ars Technica, I had a piece about how LHC physicists are using machine learning to untangle the implications of quantum interference.
As a journalist, it’s really easy to fall into a trap where you give the main person you interview too much credit: after all, you’re approaching the story from their perspective. I tried to be cautious about this, only to be stymied when literally everyone else I interviewed praised Aishik Ghosh to the skies and credited him with being the core motivating force behind the project. So I shrugged my shoulders and followed suit. My understanding is that he has been appropriately rewarded and will soon be a professor at Georgia Tech.
I didn’t list the inventors of the NSBI method that Ghosh and co. used, but names like Kyle Cranmer and Johann Brehmer tend to get bandied about. It’s a method that was originally explored for a more general goal, trying to characterize what the Standard Model might be missing, while the work I talk about in the piece takes it in a new direction, closer to the typical things the ATLAS collaboration looks for.
I also did not say nearly as much as I was tempted to about how the ATLAS collaboration publishes papers, which was honestly one of the most intriguing parts of the story for me. There is a huge amount of review that goes on inside ATLAS before one of their papers reaches the outside world, way more than there ever is in a journal’s peer review process. This is especially true for “physics papers”, where ATLAS is announcing a new conclusion about the physical world, as ATLAS’s reputation stands on those conclusions being reliable. That means starting with an “internal note” that’s hundreds of pages long (and sometimes over a thousand), an editorial board that manages the editing process, disseminating the paper to the entire collaboration for comment, and getting specific experts and institute groups within the collaboration to read through the paper in detail. The process is a bit less onerous for “technical papers”, which describe a new method, not a new conclusion about the world. Still, it’s cumbersome enough that for those papers, often scientists don’t publish them “within ATLAS” at all, instead releasing them independently. The results I reported on are special because they involved a physics paper and a technical paper, both within the ATLAS collaboration process. Instead of just working with partial or simplified data, they wanted to demonstrate the method on a “full analysis”, with all the computation and human coordination that requires. Normally, ATLAS wouldn’t go through the whole process of publishing a physics paper without basing it on new data, but this was different: the method had the potential to be so powerful that the more precise results would be worth stating as physics results alone.
(Also, for the people in the comments worried about training a model on old data: that’s not what they did. In physics, they don’t try to train a neural network model to predict the results of colliders, such a model wouldn’t tell us anything useful. They run colliders to tell us whether what they see matches the analytic, Standard, model. The neural network is trained to predict not what the experiment will say, but what the Standard Model will say, as we can usually only figure that out through time-consuming simulations. So it’s trained on (new) simulations, not on experimental data.)
Finally, on Friday I had a piece in Physics Today about the European Strategy for Particle Physics (or ESPP), and in particular, plans for the next big collider.
Before I even started working on this piece, I saw a thread by Patrick Koppenburg on some of the 263 documents submitted for the ESPP update. While my piece ended up mostly focused on the big circular collider plan that most of the field is converging on (the future circular collider, or FCC), Koppenburg’s thread was more wide-ranging, meant to illustrate the breadth of ideas under discussion. Some of that discussion is about the LHC’s current plans, like its “high-luminosity” upgrade that will see it gather data at much higher rates up until 2040. Some of it is assessing broader concerns, which it may surprise some of you to learn includes sustainability: yes, there are more or less sustainable ways to build giant colliders.
The most fun part of the discussion, though, concerns all of the other collider proposals.
Some report progress on new technologies. Muon colliders are the most famous of these, but there are other proposals that would specifically help with a linear collider. I never did end up understanding what Cooled Copper Colliders are all about, beyond that they let you get more energy in a smaller machine without super-cooling. If you know about them, chime in in the comments! Meanwhile, plasma wakefield acceleration could accelerate electrons on a wave of plasma. This has the disadvantage that you want to collide electrons and positrons, and if you try to stick a positron in plasma it will happily annihilate with the first electron it meets. So what do you do? You go half-and-half, with the HALHF project: speed up the electron with a plasma wakefield, accelerate the positron normally, and have them meet in the middle.
Others are backup plans, or “budget options”, where CERN could get a bit better measurements on some parameters if they can’t stir up the funding to measure the things they really want. They could put electrons and positrons into the LHC tunnel instead of building a new one, for a weaker machine that could still study the Higgs boson to some extent. They could use a similar experiment to produce Z bosons instead, which could serve as a bridge to a different collider project. Or, they could collider the LHC’s proton beam with an electron beam, for an experiment that mixes advantages and disadvantages of some of the other approaches.
While working on the piece, one resource I found invaluable was this colloquium talk by Tristan du Pree, where he goes through the 263 submissions and digs up a lot of interesting numbers and commentary. Read the slides for quotes from the different national inputs and “solo inputs” with comments from particular senior scientists. I used that talk to get a broad impression of what the community was feeling, and it was interesting how well it was reflected in the people I interviewed. The physicist based in Switzerland felt the most urgency for the FCC plan, while the Dutch sources were more cautious, with other Europeans firmly in the middle.
Going over the FCC report itself, one thing I decided to leave out of the discussion was the cost-benefit analysis. There’s the potential for a cute sound-bite there, “see, the collider is net positive!”, but I’m pretty skeptical of the kind of analysis they’re doing there, even if it is standard practice for government projects. Between the biggest benefits listed being industrial benefits to suppliers and early-career researcher training (is a collider unusually good for either of those things, compared to other ways we spend money?) and the fact that about 10% of the benefit is the science itself (where could one possibly get a number like that?), it feels like whatever reasoning is behind this is probably the kind of thing that makes rigor-minded economists wince. I wasn’t able to track down the full calculation though, so I really don’t know, maybe this makes more sense than it looks.
I think a stronger argument than anything along those lines is a much more basic point, about expertise. Right now, we have a community of people trying to do something that is not merely difficult, but fundamental. This isn’t like sending people to space, where many of the engineering concerns will go away when we can send robots instead. This is fundamental engineering progress in how to manipulate the forces of nature (extremely powerful magnets, high voltages) and process huge streams of data. Pushing those technologies to the limit seems like it’s going to be relevant, almost no matter what we end up doing. That’s still not putting the science first and foremost, but it feels a bit closer to an honest appraisal of what good projects like this do for the world.




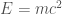 . In the mid-20th century these particle colliders were serious pieces of machinery, but still small enough to make industrial: now, there are so-called medical accelerators in many hospitals based on their designs. But current particle accelerators are a different beast, massive facilities built by international collaborations. This is the Energy Frontier.
. In the mid-20th century these particle colliders were serious pieces of machinery, but still small enough to make industrial: now, there are so-called medical accelerators in many hospitals based on their designs. But current particle accelerators are a different beast, massive facilities built by international collaborations. This is the Energy Frontier.