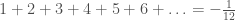
If you follow Numberphile on YouTube or Bad Astronomy on Slate you’ve already seen this counter-intuitive sum written out. Similarly, if you follow those people or Sciencetopia’s Good Math, Bad Math, you’re aware that the way that sum was presented by Numberphile in that video was seriously flawed.
There is a real sense in which adding up all of the natural numbers (numbers 1, 2, 3…) really does give you minus twelve, despite all the reasons this should be impossible. However, there is also a real sense in which it does not, and cannot, do any such thing. To explain this, I’m going to introduce two concepts: complex analysis and regularization.
This discussion is not going to be mathematically rigorous, but it should give an authentic and accurate view of where these results come from. If you’re interested in the full mathematical details, a later discussion by Numberphile should help, and the mathematically confident should read Terence Tao’s treatment from back in 2010.
With that said, let’s talk about sums! Well, one sum in particular:
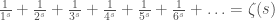
If s is greater than one, then each term in this infinite sum gets smaller and smaller fast enough that you can add them all up and get a number. That number is referred to as  , the Riemann Zeta Function.
, the Riemann Zeta Function.
So what if s is smaller than one?
The infinite sum that I described doesn’t converge for s less than one. Add it up in any reasonable way, and it just approaches infinity. Put another way, the sum is not properly defined. But despite this, is not infinite for s less than one!
Now as you might object, we only defined the Riemann Zeta Function for s greater than one. How do we know anything at all about it for s less than one?
That is where complex analysis comes in. Complex analysis sounds like a made-up term for something unreasonably complicated, but it’s quite a bit more approachable when you know what it means. Analysis is the type of mathematics that deals with functions, infinite series, and the basis of calculus. It’s often contrasted with Algebra, which usually considers mathematical concepts that are discrete rather than smooth (this definition is a huge simplification, but it’s not very relevant to this post). Complex means that complex analysis deals with functions, not of everyday real numbers, but of complex numbers, or numbers with an imaginary part.
So what does complex analysis say about the Riemann Zeta Function?
One of the most impressive results of complex analysis is the discovery that if a function of a complex number is sufficiently smooth (the technical term is analytic) then it is very highly constrained. In particular, if you know how the function behaves over an area (technical term: open set), then you know how it behaves everywhere else!
If you’re expecting me to explain why this is true, you’ll be disappointed. This is serious mathematics, and serious mathematics isn’t the sort of thing you can give the derivation for in a few lines. It takes as much effort and knowledge to replicate a mathematical result as it does to replicate many lab results in science.
What I can tell you is that this sort of approach crops up in many places, and is part of a general theme. There is a lot you can tell about a mathematical function just by looking at its behavior in some limited area, because mathematics is often much more constrained than it appears. It’s the same sort of principle behind the work I’ve been doing recently.
In the case of the Riemann Zeta Function, we have a definition for s greater than one. As it turns out, this definition still works if s is a complex number, as long as the real part of s is greater than one. Using this information, the value of the Riemann Zeta Function for a large area (half of the complex numbers), complex analysis tells us its value for every other number. In particular, it tells us this:
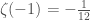
If the Riemann Zeta Function is consistently defined for every complex number, then it must have this value when s is minus one.
If we still trusted the sum definition for this value of s, we could plug in -1 and get
Does that make this statement true? Sort of. It all boils down to a concept from physics called regularization.
In physics, we know that in general there is no such thing as infinity. With a few exceptions, nothing in nature should be infinite, and finite evidence (without mathematical trickery) should never lead us to an infinite conclusion.
Despite this, occasionally calculations in physics will give infinite results. Almost always, this is evidence that we are doing something wrong: we are not thinking hard enough about what’s really going on, or there is something we don’t know or aren’t taking into account.
Doing physics research isn’t like taking a physics class: sometimes, nobody knows how to do the problem correctly! In many cases where we find infinities, we don’t know enough about “what’s really going on” to correct them. That’s where regularization comes in handy.
Regularization is the process by which an infinite result is replaced with a finite result (made “regular”), in a way so that it keeps the same properties. These finite results can then be used to do calculations and make predictions, and so long as the final predictions are regularization independent (that is, the same if you had done a different regularization trick instead) then they are legitimate.
In string theory, one way to compute the required dimensions of space and time ends up giving you an infinite sum, a sum that goes 1+2+3+4+5+…. In context, this result is obviously wrong, so we regularize it. In particular, we say that what we’re really calculating is the Riemann Zeta Function, which we happen to be evaluating at -1. Then we replace 1+2+3+4+5+… with -1/12.
Now remember when I said that getting infinities is a sign that you’re doing something wrong? These days, we have a more rigorous way to do this same calculation in string theory, one that never forces us to take an infinite sum. As expected, it gives the same result as the old method, showing that the old calculation was indeed regularization independent.
Sometimes we don’t have a better way of doing the calculation, and that’s when regularization techniques come in most handy. A particular family of tricks called renormalization is quite important, and I’ll almost certainly discuss it in a future post.
So can you really add up all the natural numbers and get -1/12? No. But if a calculation tells you to add up all the natural numbers, and it’s obvious that the result can’t be infinite, then it may secretly be asking you to calculate the Riemann Zeta Function at -1. And that, as we know from complex analysis, is indeed -1/12.




















