I’ve got a new paper up on arXiv this week.
(For those of you unfamiliar with it, arXiv.org is a website where physicists, mathematicians, and researchers in related fields post their papers before submitting them to journals. It’s a cultural quirk of physics that probably requires a post in its own right at some point. Anyway…)
What’s it about? Well, the paper is titled Hexagon functions and the three-loop remainder function. Let’s go through that and figure out what it means.
When the paper refers to hexagon functions, it’s referring to functions used to describe situations with six particles involved. An important point to clarify here is that when counting the number of “particles involved”, we add together both the particles that go in and the particles that go out. So if three particles arrive somewhere, interact with each other in some complicated way, and then those three particles leave, that’s a six-particle process. Similarly, if two particles collide and four particles emerge, that’s also a six-particle process. (If you find the idea of more particles coming out than went in confusing, read this post.) Hexagon functions, then, can describe either of those processes.
What, specifically, are these functions being used for? Well, they’re being used to find the three-loop remainder function of N=4 super Yang-Mills.
N=4 super Yang-Mills is my favorite theory. If you haven’t read my posts on the subject, I encourage you to do so.
N=4 super Yang-Mills is so nice because it is so symmetric, and because it takes part in so many dualities. These two traits ended up being enough for Zvi Bern, Lance Dixon, and Vladimir Smirnov to propose an ansatz for all amplitudes in N=4 super Yang-Mills, called the BDS ansatz. (Amplitudes are how we calculate the probability of events occurring: for example, the probability of that “two particles going to four particles” situation I talked about earlier.)
Unfortunately, their formula was incomplete. While it was possible to prove that the formula was true for four-particle and five-particle processes, for six or more particles the formula failed. As it turned out though, it failed in a predictable way. All that was needed to fix it was to add something called the remainder function, the remaining part of the formula beyond the BDS ansatz.
The task, then, was to compute this remainder function.
I’ve talked before about how in quantum field theory, we calculate probabilities through increasingly complicated diagrams, keeping track of the complexity by counting the number of loops. The remainder function had already been computed up to two loops by working out these diagrams, but three looked to be considerably more difficult.
Luckily, we (myself, Lance Dixon, James Drummond, and Jeffrey Pennington) had a trick up our sleeves.
Formulas in N=4 super Yang-Mills have a property called maximal transcendentality. I’ve talked about transcendentality before: essentially, it’s a way of counting how many powers of pi and logarithms are in your equations. Maximal transcendentality means that every part of the formula has a fixed, maximum number for its degree of transcendentality. In the case of the remainder function, this is two times the number of loops. Thus, the two-loop remainder function has degree of transcendentality four, so it can have pi to the fourth power in it, while the three-loop remainder function (the one that we calculated) has degree of transcendentality six, so it can have pi to the sixth power.
Of course, it can have lots of other expressions as well, which brings us back to the hexagon functions. By classifying the sort of functions that can appear in these formulas at each level of transcendentality, we find the basic building blocks that can show up in the remainder function. All we have to do then is ask what combinations of building blocks are allowed: which ones make good physics sense, for example, or which ones allow our formula to agree with the predictions of other researchers.
As it turns out, once you apply all the restrictions there is only one possible way to put the building blocks together that gives you a functioning formula. By process of elimination, this formula must be the correct three-loop six-point remainder function. Every extra constraint then serves as a check that nothing went wrong and that the formula is sound. Without calculating a single Feynman diagram, we’ve gotten our result!
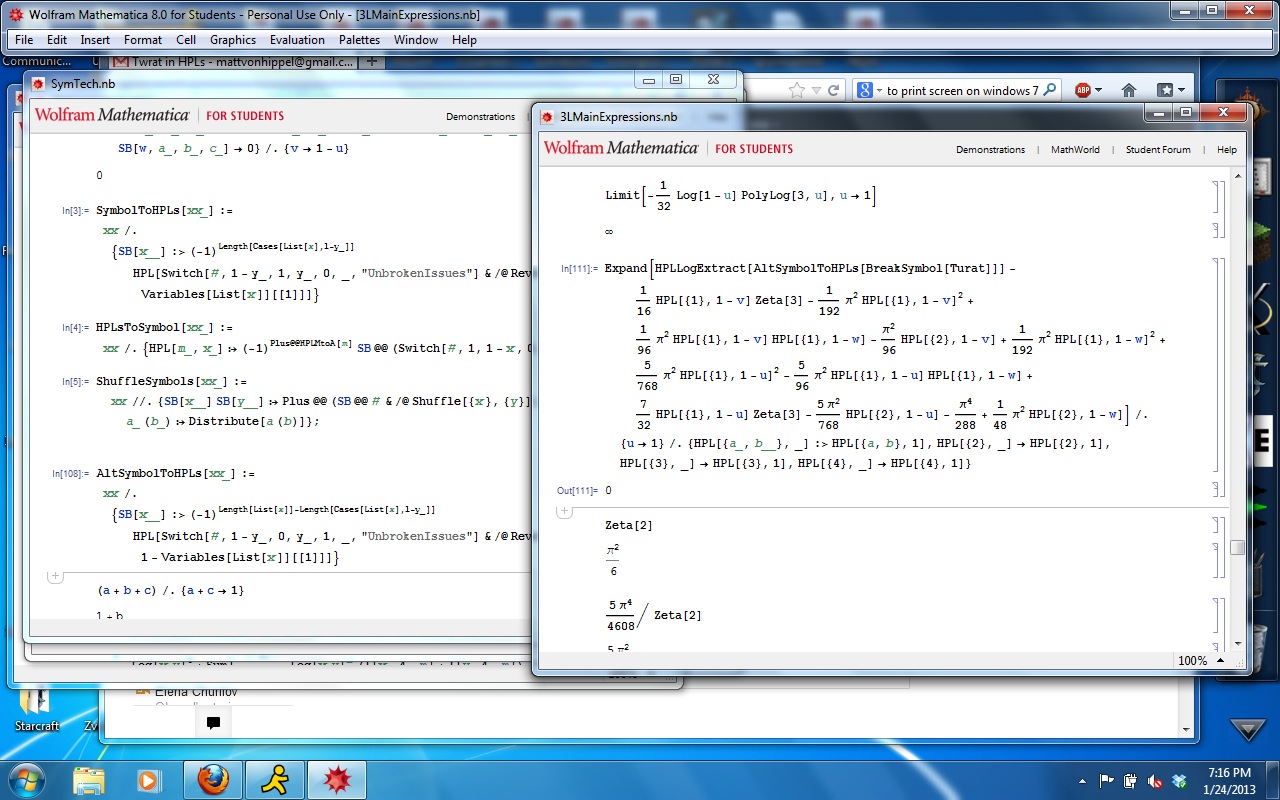
Just to give you an idea of how complicated this result is, in order to write the formula out fully would take 800 pages. We’ve got shorter ways to summarize it, but perhaps it would be better to give a picture. The formula depends on three variables, called u, v, and w. To show how the formula behaves when all three variables change, here’s a plot of the formula in the variables u and v, for a series of different values of w.

Without our various shortcuts to generate this formula, it would have taken an extraordinarily long amount of time. Luckily, N=4 super Yang-Mills’s nice properties save the day, and allow us to achieve what I hope you won’t mind me calling a truly impressive result.


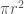 , pi is particularly interesting in that you cannot write an algebra equation made up of whole numbers whose solution is pi. While you can easily get fractions (
, pi is particularly interesting in that you cannot write an algebra equation made up of whole numbers whose solution is pi. While you can easily get fractions ( gives
gives 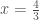 ) and even many irrational numbers (
) and even many irrational numbers ( gives
gives  ), pi is one of a set of numbers that it is impossible to get. These special numbers transcend other numbers, in that you cannot use more everyday numbers to get to them, and as such mathematicians call them transcendental numbers.
), pi is one of a set of numbers that it is impossible to get. These special numbers transcend other numbers, in that you cannot use more everyday numbers to get to them, and as such mathematicians call them transcendental numbers.
 , to find
, to find
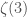
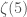 , it hasn’t even been proven that the number is actually transcendental at all! However, physicists still use the concept of transcendental weight because it allows us to classify and manipulate a common and useful set of functions.
, it hasn’t even been proven that the number is actually transcendental at all! However, physicists still use the concept of transcendental weight because it allows us to classify and manipulate a common and useful set of functions.