
Earlier this year, I had a paper about the weird multi-dimensional curves you get when you try to compute trickier and trickier Feynman diagrams. These curves were “Calabi-Yau”, a type of curve string theorists have studied as a way to curl up extra dimensions to preserve something called supersymmetry. At the time, string theorists asked me why Calabi-Yau curves showed up in these Feynman diagrams. Do they also have something to do with supersymmetry?
I still don’t know the general answer. I don’t know if all Feynman diagrams have Calabi-Yau curves hidden in them, or if only some do. But for a specific class of diagrams, I now know the reason. In this week’s paper, with Jacob Bourjaily, Andrew McLeod, and Matthias Wilhelm, we prove it.
We just needed to look at some more exotic beasts to figure it out.

Like this guy!
Meet the tardigrade. In biology, they’re incredibly tenacious microscopic animals, able to withstand the most extreme of temperatures and the radiation of outer space. In physics, we’re using their name for a class of Feynman diagrams.

A clear resemblance!
There is a long history of physicists using whimsical animal names for Feynman diagrams, from the penguin to the seagull (no relation). We chose to stick with microscopic organisms: in addition to the tardigrades, we have paramecia and amoebas, even a rogue coccolithophore.
The diagrams we look at have one thing in common, which is key to our proof: the number of lines on the inside of the diagram (“propagators”, which represent “virtual particles”) is related to the number of “loops” in the diagram, as well as the dimension. When these three numbers are related in the right way, it becomes relatively simple to show that any curves we find when computing the Feynman diagram have to be Calabi-Yau.
This includes the most well-known case of Calabi-Yaus showing up in Feynman diagrams, in so-called “banana” or “sunrise” graphs. It’s closely related to some of the cases examined by mathematicians, and our argument ended up pretty close to one made back in 2009 by the mathematician Francis Brown for a different class of diagrams. Oddly enough, neither argument works for the “traintrack” diagrams from our last paper. The tardigrades, paramecia, and amoebas are “more beastly” than those traintracks: their Calabi-Yau curves have more dimensions. In fact, we can show they have the most dimensions possible at each loop, provided all of our particles are massless. In some sense, tardigrades are “as beastly as you can get”.
We still don’t know whether all Feynman diagrams have Calabi-Yau curves, or just these. We’re not even sure how much it matters: it could be that the Calabi-Yau property is a red herring here, noticed because it’s interesting to string theorists but not so informative for us. We don’t understand Calabi-Yaus all that well yet ourselves, so we’ve been looking around at textbooks to try to figure out what people know. One of those textbooks was our inspiration for the “bestiary” in our title, an author whose whimsy we heartily approve of.


Like the classical bestiary, we hope that ours conveys a wholesome moral. There are much stranger beasts in the world of Feynman diagrams than anyone suspected.





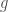 or
or 

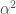 is greater than
is greater than 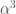 .
. 
 . It’s a family of diagrams that we can write down for any number of loops: to get more loops, just extend the “…”, adding more boxes in the middle. Count the number of lines sticking out, and you get six: these are “hexagon functions”, the type of function
. It’s a family of diagrams that we can write down for any number of loops: to get more loops, just extend the “…”, adding more boxes in the middle. Count the number of lines sticking out, and you get six: these are “hexagon functions”, the type of function 


