It’s an open secret that many physicists end up leaving physics. How many depends on how you count things, but for a representative number, this report has 31% of US physics PhDs in the private sector after one year. I’d expect that number to grow with time post-PhD. While some of these people might still be doing physics, in certain sub-fields that isn’t really an option: it’s not like there are companies that do R&D in particle physics, astrophysics, or string theory. Instead, these physicists get hired in data science, or quantitative finance, or machine learning. Others stay in academia, but stop doing physics: either transitioning to another field, or taking teaching-focused jobs that don’t leave time for research.
There’s a standard economic narrative for why this happens. The number of students grad schools accept and graduate is much higher than the number of professor jobs. There simply isn’t room for everyone, so many people end up doing something else instead.
That narrative is probably true, if you zoom out far enough. On the ground, though, the reasons people leave academia don’t feel quite this “economic”. While they might be indirectly based on a shortage of jobs, the direct reasons matter. Physicists leave physics for a wide variety of reasons, and many of them are things the field could improve on. Others are factors that will likely be present regardless of how many students graduate, or how many jobs there are. I worry that an attempt to address physics attrition on a purely economic level would miss these kinds of details.
I thought I’d talk in this post about a few reasons why physicists leave physics. Most of this won’t be new information to anyone, but I hope some of it is at least a new perspective.
First, to get it out of the way: almost no-one starts a physics PhD with the intention of going into industry. I’ve met a grand total of one person who did, and he’s rather unusual. Almost always, leaving physics represents someone’s dreams not working out.
Sometimes, that just means realizing you aren’t suited for physics. These are people who feel like they aren’t able to keep up with the material, or people who find they aren’t as interested in it as they expected. In my experience, people realize this sort of thing pretty early. They leave in the middle of grad school, or they leave once they have their PhD. In some sense, this is the healthy sort of attrition: without the ability to perfectly predict our interests and abilities, there will always be people who start a career and then decide it’s not for them.
I want to distinguish this from a broader reason to leave, disillusionment. These are people who can do physics, and want to do physics, but encounter a system that seems bent on making them do anything but. Sometimes this means disillusionment with the field itself: phenomenologists sick of tweaking models to lie just beyond the latest experimental bounds, or theorists who had hoped to address the real world but begin to see that they can’t. This kind of motivation lay behind several great atomic physicists going into biology after the second world war, to work on “life rather than death”. Sometimes instead it’s disillusionment with academia: people who have been bludgeoned by academic politics or bureaucracy, who despair of getting the academic system to care about real research or teaching instead of its current screwed-up priorities or who just don’t want to face that kind of abuse again.
When those people leave, it’s at every stage in their career. I’ve seen grad students disillusioned into leaving without a PhD, and successful tenured professors who feel like the field no longer has anything to offer them. While occasionally these people just have a difference of opinion, a lot of the time they’re pointing out real problems with the system, problems that actually should be fixed.
Sometimes, life intervenes. The classic example is the two-body problem, where you and your spouse have trouble finding jobs in the same place. There aren’t all that many places in the world that hire theoretical physicists, and still fewer with jobs open. One or both partners end up needing to compromise, and that can mean switching to a career with a bit more choice in location. People also move to take care of their parents, or because of other connections.
This seems closer to the economic picture, but I don’t think it quite lines up. Even if there were a lot fewer physicists applying for the same number of jobs, it’s still not certain that there’s a job where you want to live, specifically. You’d still end up with plenty of people leaving the field.
A commenter here frequently asks why physicists have to travel so much. Especially for a theorist, why can’t we just work remotely? With current technology, shouldn’t that be pretty easy to do?
I’ve done a lot of remote collaboration, it’s not impossible. But there really isn’t a substitute for working in the same place, for being able to meet someone in the hall and strike up a conversation around a blackboard. Remote collaborations are an ok way to keep a project going, but a rough way to start one. Institutes realize this, which is part of why most of the time they’ll only pay you a salary if they think you’re actually going to show up.
Could I imagine this changing? Maybe. The technology doesn’t exist right now, but maybe someday someone will design a social network with the right features, one where you can strike up and work on collaborations as naturally as you can in person. Then again, maybe I’m silly for imagining a technological solution to the problem in the first place.
What about more direct economic reasons? What about when people leave because of the academic job market itself?
This certainly happens. In my experience though, a lot of the time it’s pre-emptive. You’d think that people would apply for academic jobs, get rejected, and quit the field. More often, I’ve seen people notice the competition for jobs and decide at the outset that it’s not worth it for them. Sometimes this happens right out of grad school. Other times it’s later. In the latter case, these are often people who are “keeping up”, in that their career is moving roughly as fast as everyone else’s. Rather, it’s the stress, of keeping ahead of the field and marketing themselves and applying for every grant in sight and worrying that it could come crashing down any moment, that ends up too much to deal with.
What about the people who do get rejected over and over again?
Physics, like life in Jurassic Park, finds a way. Surprisingly often, these people manage to stick around. Without faculty positions they scrabble up postdoc after postdoc, short-term position after short-term position. They fund their way piece by piece, grant by grant. Often they get depressed, and cynical, and pissed off, and insist that this time they’re just going to quit the field altogether. But from what I’ve seen, once someone is that far in, they often don’t go through with it.
If fewer people went to physics grad school, or more professors were hired, would fewer people leave physics? Yes, absolutely. But there’s enough going on here, enough different causes and different motivations, that I suspect things wouldn’t work out quite as predicted. Some attrition is here to stay, some is independent of the economics. And some, perhaps, is due to problems we ought to actually solve.


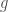 or
or 

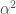 is greater than
is greater than 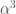 .
. 
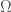 . It’s a family of diagrams that we can write down for any number of loops: to get more loops, just extend the “…”, adding more boxes in the middle. Count the number of lines sticking out, and you get six: these are “hexagon functions”, the type of function
. It’s a family of diagrams that we can write down for any number of loops: to get more loops, just extend the “…”, adding more boxes in the middle. Count the number of lines sticking out, and you get six: these are “hexagon functions”, the type of function 




 loops, N=4 super Yang-Mills diverges in dimension
loops, N=4 super Yang-Mills diverges in dimension  . From that formula, you can see that no matter how much you increase
. From that formula, you can see that no matter how much you increase