
I’ve got a new paper out this week, a continuation of a story that has threaded through my career since grad school. With a growing collaboration (now Simon Caron-Huot, Lance Dixon, Falko Dulat, Andrew McLeod, and Georgios Papathanasiou) I’ve been calculating six-particle scattering amplitudes in my favorite theory-that-does-not-describe-the-real-world, N=4 super Yang-Mills. We’ve been pushing to more and more “loops”: tougher and tougher calculations that approximate the full answer better and better, using the “word jumble” trick I talked about in Scientific American. And each time, we learn something new.
Now we’re up to seven loops for some types of particles, and six loops for the rest. In older blog posts I talked in megabytes: half a megabyte for three loops, 15 MB for four loops, 300 MB for five loops. I don’t have a number like that for six and seven loops: we don’t store the result in that way anymore, it just got too cumbersome. We have to store it in a simplified form, and even that takes 80 MB.
Some of what we learned has to do with the types of mathematical functions that we need: our “guess” for the result at each loop. We’ve honed that guess down a lot, and discovered some new simplifications along the way. I won’t tell that story here (except to hint that it has to do with “cosmic Galois theory”) because we haven’t published it yet. It will be out in a companion paper soon.
This paper focused on the next step, going from our guess to the correct six- and seven-loop answers. Here too there were surprises. For the last several loops, we’d observed a surprisingly nice pattern: different configurations of particles with different numbers of loops were related, in a way we didn’t know how to explain. The pattern stuck around at five loops, so we assumed it was the real deal, and guessed the new answer would obey it too.
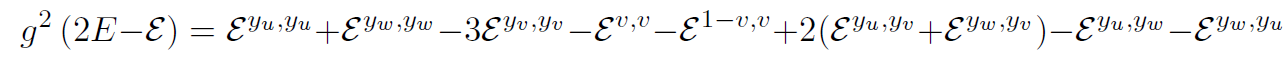
Usually when scientists tell this kind of story, the pattern works, it’s a breakthrough, everyone gets a Nobel prize, etc. This time? Nope!
The pattern failed. And it failed in a way that was surprisingly difficult to detect.
The way we calculate these things, we start with a guess and then add what we know. If we know something about how the particles behave at high energies, or when they get close together, we use that to pare down our guess, getting rid of pieces that don’t fit. We kept adding these pieces of information, and each time the pattern seemed ok. It was only when we got far enough into one of these approximations that we noticed a piece that didn’t fit.
That piece was a surprisingly stealthy mathematical function, one that hid from almost every test we could perform. There aren’t any functions like that at lower loops, so we never had to worry about this before. But now, in the rarefied land of six-loop calculations, they finally start to show up.
We have another pattern, like the old one but that isn’t broken yet. But at this point we’re cautious: things get strange as calculations get more complicated, and sometimes the nice simplifications we notice are just accidents. It’s always important to check.
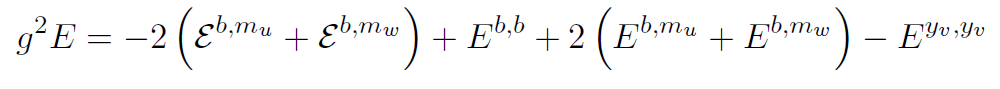
This result was a long time coming. Coordinating a large project with such a widely spread collaboration is difficult, and sometimes frustrating. People get distracted by other projects, they have disagreements about what the paper should say, even scheduling Skype around everyone’s time zones is a challenge. I’m more than a little exhausted, but happy that the paper is out, and that we’re close to finishing the companion paper as well. It’s good to have results that we’ve been hinting at in talks finally out where the community can see them. Maybe they’ll notice something new!






 over
over  . You can write:
. You can write:

 , what do you know about this sum?
, what do you know about this sum? and
and  and
and  , or
, or  and
and 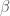 . You could even use different letters in each term, if you wanted to. You could even just pick one term, and swap
. You could even use different letters in each term, if you wanted to. You could even just pick one term, and swap 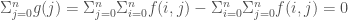
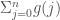 is zero.
is zero.