
Scientists have different goals when they communicate, leading to different styles, or registers, of communication. If you don’t notice what register a scientist is using, you might think they’re saying something they’re not. And if you notice someone using the wrong register for a situation, they may not actually be a scientist.
Sometimes, a scientist is trying to explain an idea to the general public. The point of these explanations is to give you appreciation and intuition for the science, not to understand it in detail. This register makes heavy use of metaphors, and sometimes also slogans. It should almost never be taken literally, and a contradiction between two different scientist explanations usually just means they are using incompatible metaphors for the same concept. Sometimes, scientists who do this a lot will comment on other metaphors you might have heard, referencing other slogans to help explain what those explanations miss. They do this knowing that they do, in the end, agree on the actual science: they’re just trying to give you another metaphor, with a deeper intuition for a neglected part of the story.
Other times, scientists are trying to teach a student to be able to do something. Teaching can use metaphors or slogans as introductions, but quickly moves past them, because it wants to show the students something they can use: an equation, a diagram, a classification. If a scientist shows you any of these equations/diagrams/classifications without explaining what they mean, then you’re not the student they had in mind: they had designed their lesson for someone who already knew those things. Teaching may convey the kinds of appreciation and intuition that explanations for the general public do, but that goal gets much less emphasis. The main goal is for students with the appropriate background to learn to do something new.
Finally, sometimes scientists are trying to advocate for a scientific point. In this register, and only in this register, are they trying to convince people who don’t already trust them. This kind of communication can include metaphors and slogans as decoration, but the bulk will be filled with details, and those details should constitute evidence: they should be a structured argument, one that lays out, scientifically, why others should come to the same conclusion.
A piece that tries to address multiple audiences can move between registers in a clean way. But if the register jumps back and forth, or if the wrong register is being used for a task, that usually means trouble. That trouble can be simple boredom, like a scientist’s typical conference talk that can’t decide whether it just wants other scientists to appreciate the work, whether it wants to teach them enough to actually use it, or whether it needs to convince any skeptics. It can also be more sinister: a lot of crackpots write pieces that are ostensibly aimed at convincing other scientists, but are almost entirely metaphors and slogans, pieces good at tugging on the general public’s intuition without actually giving scientists anything meaningful to engage with.
If you’re writing, or speaking, know what register you need to use to do what you’re trying to do! And if you run into a piece that doesn’t make sense, consider that it might be in a different register than you thought.






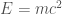 . In the mid-20th century these particle colliders were serious pieces of machinery, but still small enough to make industrial: now, there are so-called medical accelerators in many hospitals based on their designs. But current particle accelerators are a different beast, massive facilities built by international collaborations. This is the Energy Frontier.
. In the mid-20th century these particle colliders were serious pieces of machinery, but still small enough to make industrial: now, there are so-called medical accelerators in many hospitals based on their designs. But current particle accelerators are a different beast, massive facilities built by international collaborations. This is the Energy Frontier.