As part of the pedagogy course I’ve been taking, I’m doing a few guest lectures in various courses. I’ve got one coming up in a classical mechanics course (“intermediate”-level, so not Newton’s laws, but stuff the general public doesn’t know much about like Hamiltonians). They’ve been speeding through the core content, so I got to cover a “fun” topic, and after thinking back to my grad school days I chose a topic I think they’ll have a lot of fun with: Chaos theory.
Getting the obligatory Warhammer reference out of the way now
Chaos is one of those things everyone has a vague idea about. People have heard stories where a butterfly flaps its wings and causes a hurricane. Maybe they’ve heard of the rough concept, determinism with strong dependence on the initial conditions, so a tiny change (like that butterfly) can have huge consequences. Maybe they’ve seen pictures of fractals, and got the idea these are somehow related.
Its role in physics is a bit more detailed. It’s one of those concepts that “intermediate classical mechanics” is good for, one that can be much better understood once you’ve been introduced to some of the nineteenth century’s mathematical tools. It felt like a good way to show this class that the things they’ve learned aren’t just useful for dusty old problems, but for understanding something the public thinks is sexy and mysterious.
On the one hand, there’s a big fashion right now for something called research-based teaching. That doesn’t mean “using teaching methods that are justified by research” (though you’re supposed to do that too), but rather, “tying your teaching to current scientific research”. This is a fashion that makes sense, because learning about cutting-edge research in an undergraduate classroom feels pretty cool. It lets students feel more connected with the scientific community, it inspires them to get involved, and it gets them more used to what “real research” looks like.
On the other hand, structuring your textbook based on the original research papers feels kind of lazy. There’s a reason we don’t teach Newtonian mechanics the way Newton would have. Pedagogy is supposed to be something we improve at over time: we come up with better examples and better notation, more focused explanations that teach what we want students to learn. If we just summarize a paper, we’re not really providing “added value”: we should hope, at this point, that we can do better.
Thinking about this, I think the distinction boils down to why you’re teaching the material in the first place.
With a lot of research-based teaching, the goal is to show the students how to interact with current literature. You want to show them journal papers, not because the papers are the best way to teach a concept or skill, but because reading those papers is one of the skills you want to teach.
That makes sense for very current topics, but it seems a bit weird for the example I’ve been looking at, an early study of chaos from the 60’s. It’s great if students can read current papers, but they don’t necessarily need to read older ones. (At least, not yet.)
What then, is the textbook trying to teach? Here things get a bit messy. For a relatively old topic, you’d ideally want to teach not just a vague impression of what was discovered, but concrete skills. Here though, those skills are just a bit beyond the students’ reach: chaos is more approachable than you’d think, but still not 100% something the students can work with. Instead they’re learning to appreciate concepts. This can be quite valuable, but it doesn’t give the kind of structure that a concrete skill does. In particular, it makes it hard to know what to emphasize, beyond just summarizing the original article.
In this case, I’ve come up with my own way forward. There are actually concrete skills I’d like to teach. They’re skills that link up with what the textbook is teaching, skills grounded in the concepts it’s trying to convey, and that makes me think I can convey them. It will give some structure to the lesson, a focus on not merely what I’d like the students to think but what I’d like them to do.
I won’t go into too much detail: I suspect some of the students may be reading this, and I don’t want to spoil the surprise! But I’m looking forward to class, and to getting to try another pedagogical experiment.
There’s a saying in physics, attributed to the famous genius John von Neumann: “With four parameters I can fit an elephant, and with five I can make him wiggle his trunk.”
Say you want to model something, like some surprising data from a particle collider. You start with some free parameters: numbers in your model that aren’t decided yet. You then decide those numbers, “fixing” them based on the data you want to model. Your goal is for your model not only to match the data, but to predict something you haven’t yet measured. Then you can go out and check, and see if your model works.
The more free parameters you have in your model, the easier this can go wrong. More free parameters make it easier to fit your data, but that’s because they make it easier to fit any data. Your model ends up not just matching the physics, but matching the mistakes as well: the small errors that crop up in any experiment. A model like that may look like it’s a great fit to the data, but its predictions will almost all be wrong. It wasn’t just fit, it was overfit.
We have statistical tools that tell us when to worry about overfitting, when we should be impressed by a model and when it has too many parameters. We don’t actually use these tools correctly, but they still give us a hint of what we actually want to know, namely, whether our model will make the right predictions. In a sense, these tools form the mathematical basis for Occam’s Razor, the idea that the best explanation is often the simplest one, and Occam’s Razor is a critical part of how we do science.
So, did you know machine learning was just modeling data?
All of the much-hyped recent advances in artificial intelligence, GPT and Stable Diffusion and all those folks, at heart they’re all doing this kind of thing. They start out with a model (with a lot more than five parameters, arranged in complicated layers…), then use data to fix the free parameters. Unlike most of the models physicists use, they can’t perfectly fix these numbers: there are too many of them, so they have to approximate. They then test their model on new data, and hope it still works.
Increasingly, it does, and impressively well, so well that the average person probably doesn’t realize this is what it’s doing. When you ask one of these AIs to make an image for you, what you’re doing is asking what image the model predicts would show up captioned with your text. It’s the same sort of thing as asking an economist what their model predicts the unemployment rate will be when inflation goes up. The machine learning model is just way, way more complicated.
As a physicist, the first time I heard about this, I had von Neumann’s quote in the back of my head. Yes, these machines are dealing with a lot more data, from a much more complicated reality. They literally are trying to fit elephants, even elephants wiggling their trunks. Still, the sheer number of parameters seemed fishy here. And for a little bit things seemed even more fishy, when I learned about double descent.
Suppose you start increasing the number of parameters in your model. Initially, your model gets better and better. Your predictions have less and less error, your error descends. Eventually, though, the error increases again: you have too many parameters so you’re over-fitting, and your model is capturing accidents in your data, not reality.
In machine learning, weirdly, this is often not the end of the story. Sometimes, your prediction error rises, only to fall once more, in a double descent.
For a while, I found this deeply disturbing. The idea that you can fit your data, start overfitting, and then keep overfitting, and somehow end up safe in the end, was terrifying. The way some of the popular accounts described it, like you were just overfitting more and more and that was fine, was baffling, especially when they seemed to predict that you could keep adding parameters, keep fitting tinier and tinier fleas on the elephant’s trunk, and your predictions would never start going wrong. It would be the death of Occam’s Razor as we know it, more complicated explanations beating simpler ones off to infinity.
Luckily, that’s not what happens. And after talking to a bunch of people, I think I finally understand this enough to say something about it here.
The right way to think about double descent is as overfitting prematurely. You do still expect your error to eventually go up: your model won’t be perfect forever, at some point you will really overfit. It might take a long time, though: machine learning people are trying to model very complicated things, like human behavior, with giant piles of data, so very complicated models may often be entirely appropriate. In the meantime, due to a bad choice of model, you can accidentally overfit early. You will eventually overcome this, pushing past with more parameters into a model that works again, but for a little while you might convince yourself, wrongly, that you have nothing more to learn.
So Occam’s Razor still holds, but with a twist. The best model is simple enough, but no simpler. And if you’re not careful enough, you can convince yourself that a too-simple model is as complicated as you can get.
Image from Astral Codex Ten
I was reminded of all this recently by somearticles by Sabine Hossenfelder.
Hossenfelder is a critic of mainstream fundamental physics. The articles were her restating a point she’s made many times before, including in (at least) one of her books. She thinks the people who propose new particles and try to search for them are wasting time, and the experiments motivated by those particles are wasting money. She’s motivated by something like Occam’s Razor, the need to stick to the simplest possible model that fits the evidence. In her view, the simplest models are those in which we don’t detect any more new particles any time soon, so those are the models she thinks we should stick with.
I tend to disagree with Hossenfelder. Here, I was oddly conflicted. In some of her examples, it seemed like she had a legitimate point. Others seemed like she missed the mark entirely.
Talk to most astrophysicists, and they’ll tell you dark matter is settled science. Indeed, there is a huge amount of evidence that something exists out there in the universe that we can’t see. It distorts the way galaxies rotate, lenses light with its gravity, and wiggled the early universe in pretty much the way you’d expect matter to.
What isn’t settled is whether that “something” interacts with anything else. It has to interact with gravity, of course, but everything else is in some sense “optional”. Astroparticle physicists use satellites to search for clues that dark matter has some other interactions: perhaps it is unstable, sometimes releasing tiny signals of light. If it did, it might solve other problems as well.
Hossenfelder thinks this is bunk (in part because she thinks those other problems are bunk). I kind of do too, though perhaps for a more general reason: I don’t think nature owes us an easy explanation. Dark matter isn’t obligated to solve any of our other problems, it just has to be dark matter. That seems in some sense like the simplest explanation, the one demanded by Occam’s Razor.
At the same time, I disagree with her substantially more on collider physics. At the Large Hadron Collider so far, all of the data is reasonably compatible with the Standard Model, our roughly half-century old theory of particle physics. Collider physicists search that data for subtle deviations, one of which might point to a general discrepancy, a hint of something beyond the Standard Model.
While my intuitions say that the simplest dark matter is completely dark, they don’t say that the simplest particle physics is the Standard Model. Back when the Standard Model was proposed, people might have said it was exceptionally simple because it had a property called “renormalizability”, but these days we view that as less important. Physicists like Ken Wilson and Steven Weinberg taught us to view theories as a kind of series of corrections, like a Taylor series in calculus. Each correction encodes new, rarer ways that particles can interact. A renormalizable theory is just the first term in this series. The higher terms might be zero, but they might not. We even know that some terms cannot be zero, because gravity is not renormalizable.
The two cases on the surface don’t seem that different. Dark matter might have zero interactions besides gravity, but it might have other interactions. The Standard Model might have zero corrections, but it might have nonzero corrections. But for some reason, my intuition treats the two differently: I would find it completely reasonable for dark matter to have no extra interactions, but very strange for the Standard Model to have no corrections.
I think part of where my intuition comes from here is my experience with other theories.
One example is a toy model called sine-Gordon theory. In sine-Gordon theory, this Taylor series of corrections is a very familiar Taylor series: the sine function! If you go correction by correction, you’ll see new interactions and more new interactions. But if you actually add them all up, something surprising happens. Sine-Gordon turns out to be a special theory, one with “no particle production”: unlike in normal particle physics, in sine-Gordon particles can neither be created nor destroyed. You would never know this if you did not add up all of the corrections.
String theory itself is another example. In string theory, elementary particles are replaced by strings, but you can think of that stringy behavior as a series of corrections on top of ordinary particles. Once again, you can try adding these things up correction by correction, but once again the “magic” doesn’t happen until the end. Only in the full series does string theory “do its thing”, and fix some of the big problems of quantum gravity.
If the real world really is a theory like this, then I think we have to worry about something like double descent.
Remember, double descent happens when our models can prematurely get worse before getting better. This can happen if the real thing we’re trying to model is very different from the model we’re using, like the example in this explainer that tries to use straight lines to match a curve. If we think a model is simpler because it puts fewer corrections on top of the Standard Model, then we may end up rejecting a reality with infinite corrections, a Taylor series that happens to add up to something quite nice. Occam’s Razor stops helping us if we can’t tell which models are really the simple ones.
The problem here is that every notion of “simple” we can appeal to here is aesthetic, a choice based on what makes the math look nicer. Other sciences don’t have this problem. When a biologist or a chemist wants to look for the simplest model, they look for a model with fewer organisms, fewer reactions…in the end, fewer atoms and molecules, fewer of the building-blocks given to those fields by physics. Fundamental physics can’t do this: we build our theories up from mathematics, and mathematics only demands that we be consistent. We can call theories simpler because we can write them in a simple way (but we could write them in a different way too). Or we can call them simpler because they look more like toy models we’ve worked with before (but those toy models are just a tiny sample of all the theories that are possible). We don’t have a standard of simplicity that is actually reliable.
From the Wikipedia page for dark matter halos
There is one other way out of this pickle. A theory that is easier to write down is under no obligation to be true. But it is more likely to be useful. Even if the real world is ultimately described by some giant pile of mathematical parameters, if a simple theory is good enough for the engineers then it’s a better theory to aim for: a useful theory that makes peoples’ lives better.
I kind of get the feeling Hossenfelder would make this objection. I’ve seen her argue on twitter that scientists should always be able to say what their research is good for, and her Guardian article has this suggestive sentence: “However, we do not know that dark matter is indeed made of particles; and even if it is, to explain astrophysical observations one does not need to know details of the particles’ behaviour.”
Ok yes, to explain astrophysical observations one doesn’t need to know the details of dark matter particles’ behavior. But taking a step back, one doesn’t actually need to explain astrophysical observations at all.
Astrophysics and particle physics are not engineering problems. Nobody out there is trying to steer a spacecraft all the way across a galaxy, navigating the distribution of dark matter, or creating new universes and trying to make sure they go just right. Even if we might do these things some day, it will be so far in the future that our attempts to understand them won’t just be quaint: they will likely be actively damaging, confusing old research in dead languages that the field will be better off ignoring to start from scratch.
Because of that, usefulness is also not a meaningful guide. It cannot tell you which theories are more simple, which to favor with Occam’s Razor.
Hossenfelder’s highest-profile recent work falls afoul of one or the other of her principles. Her work on the foundations of quantum mechanics could genuinely be useful, but there’s no reason aside from claims of philosophical beauty to expect it to be true. Her work on modeling dark matter is at least directly motivated by data, but is guaranteed to not be useful.
I’m not pointing this out to call Hossenfelder a hypocrite, as some sort of ad hominem or tu quoque. I’m pointing this out because I don’t think it’s possible to do fundamental physics today without falling afoul of these principles. If you want to hold out hope that your work is useful, you don’t have a great reason besides a love of pretty math: otherwise, anything useful would have been discovered long ago. If you just try to model existing data as best you can, then you’re making a model for events far away or locked in high-energy particle colliders, a model no-one else besides other physicists will ever use.
I don’t know the way through this. I think if you need to take Occam’s Razor seriously, to build on the same foundations that work in every other scientific field…then you should stop doing fundamental physics. You won’t be able to make it work. If you still need to do it, if you can’t give up the sub-field, then you should justify it on building capabilities, on the kind of “practice” Hossenfelder also dismisses in her Guardian piece.
We don’t have a solid foundation, a reliable notion of what is simple and what isn’t. We have guesses and personal opinions. And until some experiment uncovers some blinding flash of new useful meaningful magic…I don’t think we can do any better than that.
You can think of a quantum particle like a coin frozen in mid-air. Once measured, the coin falls, and you read it as heads or tails, but before then the coin is neither, with equal chance to be one or the other. In this metaphor, quantum entanglement slices the coin in half. Slice a coin in half on a table, and its halves will either both show heads, or both tails. Slice our “frozen coin” in mid-air, and it keeps this property: the halves, both still “frozen”, can later be measured as both heads, or both tails. Even if you separate them, the outcomes never become independent: you will never find one half-coin to land on tails, and the other on heads.
Einstein thought that this couldn’t be the whole story. He was bothered by the way that measuring a “frozen” coin seems to change its behavior faster than light, screwing up his theory of special relativity. Entanglement, with its ability to separate halves of a coin as far as you liked, just made the problem worse. He thought that there must be a deeper theory, one with “hidden variables” that determined whether the halves would be heads or tails before they were separated.
Bell’s inequalities were just theory, though, until this year’s Nobelists arrived to test them. Clauser was first: in the 70’s, he proposed a variant of Bell’s inequalities, then tested them by measuring members of a pair of entangled photons in two different places. He found complete agreement with quantum mechanics.
Still, there was a loophole left for Einstein’s idea. If the settings on the two measurement devices could influence the pair of photons when they were first entangled, that would allow hidden variables to influence the outcome in a way that avoided Bell and Clauser’s calculations. It was Aspect, in the 80’s, who closed this loophole: by doing experiments fast enough to change the measurement settings after the photons were entangled, he could show that the settings could not possibly influence the forming of the entangled pair.
Aspect’s experiments, in many minds, were the end of the story. They were the ones emphasized in the textbooks when I studied quantum mechanics in school.
The remaining loopholes are trickier. Some hope for a way to correlate the behavior of particles and measurement devices that doesn’t run afoul of Aspect’s experiment. This idea, called, superdeterminism, has recently had a fewpassionateadvocates, but speaking personally I’m still confused as to how it’s supposed to work. Others want to jettison special relativity altogether. This would not only involve measurements influencing each other faster than light, but also would break a kind of symmetry present in the experiments, because it would declare one measurement or the other to have happened “first”, something special relativity forbids. The majority, uncomfortable with either approach, thinks that quantum mechanics is complete, with no deterministic theory that can replace it. They differ only on how to describe, or interpret, the theory, a debate more the domain of careful philosophy than of physics.
After all of these philosophical debates over the nature of reality, you may ask what quantum entanglement can do for you?
I’ve done a lot of work with what we like to call “bootstrap” methods. Instead of doing a particle physics calculation in all its gory detail, we start with a plausible guess and impose requirements based on what we know. Eventually, we have the right answer pulled up “by its own bootstraps”: the only answer the calculation could have, without actually doing the calculation.
This method works very well, but so far it’s only been applied to certain kinds of calculations, involving mathematical functions called polylogarithms. More complicated calculations involve a mathematical object called an elliptic curve, and until very recently it wasn’t clear how to bootstrap them. To get people thinking about it, my colleagues Hjalte Frellesvig and Andrew McLeod asked the Carlsberg Foundation (yes, that Carlsberg) to fund a mini-conference. The idea was to get elliptic people and bootstrap people together (along with Hjalte’s tribe, intersection theory people) to hash things out. “Jumpstart people” are not a thing in physics, so despite the title they were not invited.
Anyone remember these games? Did you know that they still exist, have an educational MMO, and bought neopets?
Having the conference so soon after the yearly Elliptics meeting had some strange consequences. There was only one actual duplicate talk, but the first day of talks all felt like they would have been welcome additions to the earlier conference. Some might be functioning as “overflow”: Elliptics this year focused on discussion and so didn’t have many slots for talks, while this conference despite its discussion-focused goal had a more packed schedule. In other cases, people might have been persuaded by the more relaxed atmosphere and lack of recording or posted slides to give more speculative talks. Oliver Schlotterer’s talk was likely in this category, a discussion of the genus-two functions one step beyond elliptics that I think people at the previous conference would have found very exciting, but which involved work in progress that I could understand him being cautious about presenting.
The other days focused more on the bootstrap side, with progress on some surprising but not-quite-yet elliptic avenues. It was great to hear that Mark Spradlin is making new progress on his Ziggurat story, to hear James Drummond suggest a picture for cluster algebras that could generalize to other theories, and to get some idea of the mysterious ongoing story that animates my colleague Cristian Vergu.
There was one thing the organizers couldn’t have anticipated that ended up throwing the conference into a new light. The goal of the conference was to get people started bootstrapping elliptic functions, but in the meantime people have gotten started on their own. Roger Morales Espasa presented his work on this with several of my other colleagues. They can already reproduce a known result, the ten-particle elliptic double-box, and are well on-track to deriving something genuinely new, the twelve-particle version. It’s exciting, but it definitely makes the rest of us look around and take stock. Hopefully for the better!
I had a paper two weeks ago with a Master’s student, Alex Chaparro Pozo. I haven’t gotten a chance to talk about it yet, so I thought I should say a few words this week. It’s another entry in what I’ve been calling my cabinet of curiosities, interesting mathematical “objects” I’m sharing with the world.
I calculate scattering amplitudes, formulas that give the probability that particles scatter off each other in particular ways. While in principle I could do this with any particle physics theory, I have a favorite: a “toy model” called N=4 super Yang-Mills. N=4 super Yang-Mills doesn’t describe reality, but it lets us figure out cool new calculation tricks, and these often end up useful in reality as well.
Many scattering amplitudes in N=4 super Yang-Mills involve a type of mathematical functions called polylogarithms. These functions are especially easy to work with, but they aren’t the whole story. One we start considering more complicated situations (what if two particles collide, and eight particles come out?) we need more complicated functions, called elliptic polylogarithms.
The original calculation was pretty complicated. Two particles colliding, eight particles coming out, meant that in total we had to keep track of ten different particles. That gets messy fast. I’m pretty good at dealing with six particles, not ten. Luckily, it turned out there was a way to pretend there were six particles only: by “twisting” up the calculation, we found a toy model within the toy model: a six-particle version of the calculation. Much like the original was in a theory that doesn’t describe the real world, these six particles don’t describe six particles in that theory: they’re a kind of toy calculation within the toy model, doubly un-real.
Not quintuply-unreal though
With this nested toy model, I was confident we could do the calculation. I wasn’t confident I’d have time for it, though. This ended up making it perfect for a Master’s thesis, which is how Alex got into the game.
Alex worked his way through the calculation, programming and transforming, going from one type of mathematical functions to another (at least once because I’d forgotten to tell him the right functions to use, oops!) There were more details and subtleties than expected, but in the end everything worked out.
Alex left the field (not, as far as I know, because of this). And for a while, because of that especially thorough scooping, I didn’t publish.
What changed my mind, in part, was seeing the field develop in the meantime. It turns out toy models, and even nested toy models, are quite useful. We still have a lot ofuncertainty about what to do, how to use the new calculation methods and what they imply. And usually, the best way to get through that kind of uncertainty is with simple, well-behaved toy models.
So I thought, in the end, that this might be useful. Even if it’s a toy version of something that already exists, I expect it to be an educational toy, one we can learn a lot from. So I’ve put it out into the world, as part of this year’s cabinet of curiosities.
It’s in Mainz, which you can tell from the Gutenberg street art
Elliptics has been growing in recent years, hurtling into prominence as a subfield of amplitudes (which is already a subfield of theoretical physics). This has led to growing lists of participants and a more and more packed schedule.
This year walked all of that back a bit. There were three talks a day: two one-hour talks by senior researchers and one half-hour talk by a junior researcher. The rest, as well as the whole last day, are geared to discussion. It’s an attempt to go back to the subfield’s roots. In the beginning, the Elliptics conferences drew together a small group to sort out a plan for the future, digging through the often-confusing mathematics to try to find a baseline for future progress. The field has advanced since then, but some of our questions are still almost as basic. What relations exist between different calculations? How much do we value fast numerics, versus analytical understanding? What methods do we want to preserve, and which aren’t serving us well? To answer these questions, it helps to get a few people together in one place, not to silently listen to lectures, but to question and discuss and hash things out. I may have heard a smaller range of topics at this year’s Elliptics, but due to the sheer depth we managed to probe on those fewer topics I feel like I’ve learned much more.
Since someone always asks, I should say that the talks were not recorded, but they are posting slides online, so if you’re interested in the topic you can watch there. A few people discussed new developments, some just published and some yet to be published. I discussed the work I talked about last week, and got a lot of good feedback and ideas about how to move forward.
I had two more papers out this week, continuing my cabinet of curiosities. I’ll talk about one of them today, and the other in (probably) two weeks.
This week, I’m talking about a paper I wrote with an excellent Master’s student, Andreas Forum. Andreas came to me looking for a project on the mathematical side. I had a rather nice idea for his project at first, to explain a proof in an old math paper so it could be used by physicists.
Unfortunately, the proof I sent him off to explain didn’t actually exist. Fortunately, by the time we figured this out Andreas had learned quite a bit of math, so he was ready for his next project: a coaction for Calabi-Yau Feynman diagrams.
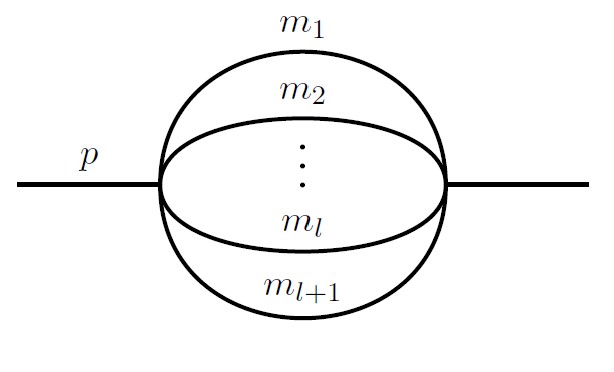
We chose to focus on one particular diagram, called a sunrise diagram for its resemblance to a sun rising over the sea:
This diagram
Feynman diagrams depict paths traveled by particles. The paths are a metaphor, or organizing tool, for more complicated calculations: computations of the chances fundamental particles behave in different ways. Each diagram encodes a complicated integral. This one shows one particle splitting into many, then those many particles reuniting into one.
Do the integrals in Feynman diagrams, and you get a variety of different mathematical functions. Many of them integrate to functions called polylogarithms, and we’ve gotten really really good at working with them. We can integrate them up, simplify them, and sometimes we can guess them so well we don’t have to do the integrals at all! We can do all of that because we know how to break polylogarithm functions apart, with a mathematical operation called a coaction. The coaction chops polylogarithms up to simpler parts, parts that are easier to work with.
More complicated Feynman diagrams give more complicated functions, though. Some of them give what are called elliptic functions. You can think of these functions as involving a geometrical shape, in this case a torus.
Other researchers had proposed a coaction for elliptic functions back in 2018. When they derived it, though, they left a recipe for something more general. Follow the instructions in the paper, and you could in principle find a coaction for other diagrams, even the Calabi-Yau ones, if you set it up right.
I had an idea for how to set it up right, and in the grand tradition of supervisors everywhere I got Andreas to do the dirty work of applying it. Despite the delay of our false start and despite the fact that this was probably in retrospect too big a project for a normal Master’s thesis, Andreas made it work!
Our result, though, is a bit weird. The coaction is a powerful tool for polylogarithms because it chops them up finely: keep chopping, and you get down to very simple functions. Our coaction isn’t quite so fine: we don’t chop our functions into as many parts, and the parts are more mysterious, more difficult to handle.
We think these are temporary problems though. The recipe we applied turns out to be a recipe with a lot of choices to make, less like Julia Child and more like one of those books where you mix-and-match recipes. We believe the community can play with the parameters of this recipe, finding new version of the coaction for new uses.
This is one of the shiniest of the curiosities in my cabinet this year, I hope it gets put to good use.
Before I launch into the post: I got interviewed on Theoretically Podcasting, a new YouTube channel focused on beginning grad student-level explanations of topics in theoretical physics. If that sounds interesting to you, check it out!
This Fall is paper season for me. I’m finishing up a number of different projects, on a number of different things. Each one was its own puzzle: a curious object found, polished, and sent off into the world.
I’ve mentioned before that the calculations I do involve a kind of “alphabet“. Break down a formula for the probability that two particles collide, and you find pieces that occur again and again. In the nicest cases, those pieces are rational functions, but they can easily get more complicated. I’ve talked before about a case where square roots enter the game, for example. But if square roots appear, what about something even more complicated? What about cubic roots?
What about 1024th roots?
Occasionally, my co-authors and I would say something like that at the end of a talk and an older professor would scoff: “Cube roots? Impossible!”
You might imagine these professors were just being unreasonable skeptics, the elderly-but-distinguished scientists from that Arthur C. Clarke quote. But while they turned out to be wrong, they weren’t being unreasonable. They were thinking back to theorems from the 60’s, theorems which seemed to argue that these particle physics calculations could only have a few specific kinds of behavior: they could behave like rational functions, like logarithms, or like square roots. Theorems which, as they understood them, would have made our claims impossible.
Eventually, we decided to figure out what the heck was going on here. We grabbed the simplest example we could find (a cube root involving three loops and eleven gluons in N=4 super Yang-Mills…yeah) and buckled down to do the calculation.
When we want to calculate something specific to our field, we can reference textbooks and papers, and draw on our own experience. Much of the calculation was like that. A crucial piece, though, involved something quite a bit less specific: calculating a cubic root. And for things like that, you can tell your teachers we use only the very best: Wikipedia.
Check out the Wikipedia entry for the cubic formula. It’s complicated, in ways the quadratic formula isn’t. It involves complex numbers, for one. But it’s not that crazy.
What those theorems from the 60’s said (and what they actually said, not what people misremembered them as saying), was that you can’t take a single limit of a particle physics calculation, and have it behave like a cubic root. You need to take more limits, not just one, to see it.
It turns out, you can even see this just from the Wikipedia entry. There’s a big cube root sign in the middle there, equal to some variable “C”. Look at what’s inside that cube root. You want that part inside to vanish. That means two things need to cancel: Wikipedia labels them , and . Do some algebra, and you’ll see that for those to cancel, you need .
So you look at the limit, . This time you need not just some algebra, but some calculus. I’ll let the students in the audience work it out, but at the end of the day, you should notice how C behaves when is small. It isn’t like . It’s like just plain . The cube root goes away.
It can come back, but only if you take another limit: not just , but as well. And that’s just fine according to those theorems from the 60’s. So our cubic curiosity isn’t impossible after all.
Our calculation wasn’t quite this simple, of course. We had to close a few loopholes, checking our example in detail using more than just Wikipedia-based methods. We found what we thought was a toy example, that turned out to be even more complicated, involving roots of a degree-six polynomial (one that has no “formula”!).
And in the end, polished and in their display case, we’ve put our examples up for the world to see. Let’s see what people think of them!
Quanta’s article describes how a few friends of mine (Lance Dixon, Ömer Gürdoğan, Andrew McLeod, and Matthias Wilhelm) noticed a weird pattern in two of these formulas, from two different calculations. If you flip the “words” around, back to front (an operation called the antipode), you go from a formula describing one collision of particles to a formula for totally different particles. Somehow, the two calculations are “dual”: two different-seeming descriptions that secretly mean the same thing.
Quanta quoted me for their article, and I was (pleasantly) baffled. See, the antipode was supposed to be useless. The mathematicians told us it was something the math allows us to do, like you’re allowed to order pineapple on pizza. But just like pineapple on pizza, we couldn’t imagine a situation where we actually wanted to do it.
What Quanta didn’t say was why we thought the antipode was useless. That’s a hard story to tell, one that wouldn’t fit in a piece like that.
It fits here, though. So in the rest of this post, I’d like to explain why flipping around words is such a strange, seemingly useless thing to do. It’s strange because it swaps two things that in physics we thought should be independent: branch cuts and derivatives, or particles and symmetries.
Let’s start with the first things in each pair: branch cuts, and particles.
The first few letters of our “word” tell us something mathematical, and they tell us something physical. Mathematically, they tell us ways that our formula can change suddenly, and discontinuously.
Take a logarithm, the inverse of . You’re probably used to plugging in positive numbers, and getting out something reasonable, that changes in a smooth and regular way: after all, is always positive, right? But in mathematics, you don’t have to just use positive numbers. You can use negative numbers. Even more interestingly, you can use complex numbers. And if you take the logarithm of a complex number, and look at the imaginary part, it looks like this:
Mostly, this complex logarithm still seems to be doing what it’s supposed to, changing in a nice slow way. But there is a weird “cut” in the graph for negative numbers: a sudden jump, from to . That jump is called a “branch cut”.
As physicists, we usually don’t like our formulas to make sudden changes. A change like this is an infinitely fast jump, and we don’t like infinities much either. But we do have one good use for a formula like this, because sometimes our formulas do change suddenly: when we have enough energy to make a new particle.
Imagine colliding two protons together, like at the LHC. Colliding particles doesn’t just break the protons into pieces: due to Einstein’s famous , it can create new particles as well. But to create a new particle, you need enough energy: worth of energy. So as you dial up the energy of your protons, you’ll notice a sudden change: you couldn’t create, say, a Higgs boson, and now you can. Our formulas represent some of those kinds of sudden changes with branch cuts.
So the beginning of our “words” represent branch cuts, and particles. The end represents derivatives and symmetries.
Derivatives come from the land of calculus, a place spooky to those with traumatic math class memories. Derivatives shouldn’t be so spooky though. They’re just ways we measure change. If we have a formula that is smoothly changing as we change some input, we can describe that change with a derivative.
The ending of our “words” tell us what happens when we take a derivative. They tell us which ways our formulas can smoothly change, and what happens when they do.
In doing so, they tell us about something some physicists make sound spooky, called symmetries. Symmetries are changes we can make that don’t really change what’s important. For example, you could imagine lifting up the entire Large Hadron Collider and (carefully!) carrying it across the ocean, from France to the US. We’d expect that, once all the scared scientists return and turn it back on, it would start getting exactly the same results. Physics has “translation symmetry”: you can move, or “translate” an experiment, and the important stuff stays the same.
These symmetries are closely connected to derivatives. If changing something doesn’t change anything important, that should be reflected in our formulas: they shouldn’t change either, so their derivatives should be zero. If instead the symmetry isn’t quite true, if it’s what we call “broken”, then by knowing how it was “broken” we know what the derivative should be.
So branch cuts tell us about particles, derivatives tell us about symmetries. The weird thing about the antipode, the un-physical bizarre thing, is that it swaps them. It makes the particles of one calculation determine the symmetries of another.
(And lest you’ve heard about particles with symmetries, like gluons and SU(3)…this is a different kind of thing. I don’t have enough room to explain why here, but it’s completely unrelated.)
Why the heck does this duality exist?
A commenter on the last post asked me to speculate. I said there that I have no clue, and that’s most of the answer.
If I had to speculate, though, my answer might be disappointing.
Most of the things in physics we call “dualities” have fairly deep physical meanings, linked to twisting spacetime in complicated ways. AdS/CFT isn’t fully explained, but it seems to be related to something called the holographic principle, the idea that gravity ties together the inside of space with the boundary around it. T duality, an older concept in string theory, is explained: a consequence of how strings “see” the world in terms of things to wrap around and things to spin around. In my field, one of our favorite dualities links back to this as well, amplitude-Wilson loop duality linked to fermionic T-duality.
The antipode doesn’t twist spacetime, it twists the mathematics. And it may be it matters only because the mathematics is so constrained that it’s forced to happen.
The trick that Lance Dixon and co. used to discover antipodal duality is the same trick I used with Lance to calculate complicated scattering amplitudes. It relies on taking a general guess of words in the right “alphabet”, and constraining it: using mathematical and physical principles it must obey and throwing out every illegal answer until there’s only one answer left.
Currently, there are some hints that the principles used for the different calculations linked by antipodal duality are “antipodal mirrors” of each other: that different principles have the same implication when the duality “flips” them around. If so, then it could be this duality is in some sense just a coincidence: not a coincidence limited to a few calculations, but a coincidence limited to a few principles. Thought of in this way, it might not tell us a lot about other situations, it might not really be “deep”.
Of course, I could be wrong about this. It could be much more general, could mean much more. But in that context, I really have no clue what to speculate. The antipode is weird: it links things that really should not be physically linked. We’ll have to see what that actually means.











 , and
, and  . Do some algebra, and you’ll see that for those to cancel, you need
. Do some algebra, and you’ll see that for those to cancel, you need  .
.  . This time you need not just some algebra, but some calculus. I’ll let the students in the audience work it out, but at the end of the day, you should notice how C behaves when
. This time you need not just some algebra, but some calculus. I’ll let the students in the audience work it out, but at the end of the day, you should notice how C behaves when 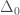 is small. It isn’t like
is small. It isn’t like ![\sqrt[3]{\Delta_0}](https://s0.wp.com/latex.php?latex=%5Csqrt%5B3%5D%7B%5CDelta_0%7D&bg=ffffff&fg=444444&s=0&c=20201002) . It’s like just plain
. It’s like just plain 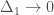 as well. And that’s just fine according to those theorems from the 60’s. So our cubic curiosity isn’t impossible after all.
as well. And that’s just fine according to those theorems from the 60’s. So our cubic curiosity isn’t impossible after all.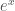 . You’re probably used to plugging in positive numbers, and getting out something reasonable, that changes in a smooth and regular way: after all,
. You’re probably used to plugging in positive numbers, and getting out something reasonable, that changes in a smooth and regular way: after all, 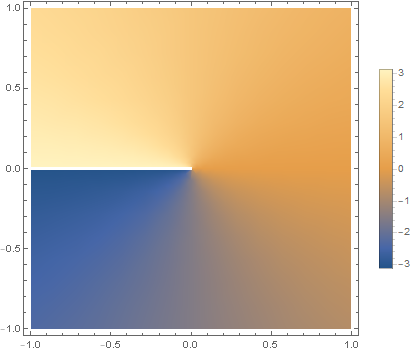
 to
to 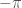 . That jump is called a “branch cut”.
. That jump is called a “branch cut”.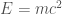 ,
,  worth of energy. So as you dial up the energy of your protons, you’ll notice a sudden change: you couldn’t create, say, a Higgs boson, and now you can. Our formulas represent some of those kinds of sudden changes with branch cuts.
worth of energy. So as you dial up the energy of your protons, you’ll notice a sudden change: you couldn’t create, say, a Higgs boson, and now you can. Our formulas represent some of those kinds of sudden changes with branch cuts.