A paper about scientific fraud has been making the rounds in social media lately. The authors gather evidence of large-scale networks of fraudsters across multiple fields, from teams of editors that fast-track fraudulent research to businesses that take over journals, sell spots for articles, and then move on to a new target when the journal is de-indexed. I’m not an expert in this kind of statistical sleuthing, but the work looks impressively thorough.
Still, I think the authors overplay their results a bit. They describe themselves as revealing something many scientists underestimate. They point to what they label as misconceptions: that scientific fraud is usually perpetrated alone by individual unethical scientists, or that it is almost entirely a problem of the developing world, and present their work as disproving those misconceptions. Listen to them, and you might get the feeling that science is rife with corruption, that no result, or scientist, can be trusted.
As far as I can tell, though, those “misconceptions” they identify are true. Someone who believes that scientific fraud is perpetrated by loners is probably right, as is someone who believes it largely takes place outside of the first world.
As is often the case, the problem is words.
“Scientific Fraud” is a single term for two different things. The two both involve bad actors twisting scientific activity. But in everything else — their incentives, their geography, their scale, and their consequences — they are dramatically different.
One of the types of scientific fraud is largely about power.
In references 84-89 of the paper, the authors give examples of large-scale scientific fraud in Europe and the US. All (except one, which I’ll mention later) are about the career of a single researcher. Each of these people systematically bent the truth, whether with dodgy statistics, doctored images, or inflating citation counts. Some seemed motivated to promote a particular scientific argument, cutting corners to push a particular conclusion through. Others were purer cases of self-promotion. These people often put pressure on students, postdocs, and other junior researchers in their orbits, which increases the scale of their impact. In some cases, their work rippled out to convince other researchers, prolonging bad ideas and strangling good ones. These were people with power, who leveraged that power to increase their power.
There also don’t appear to be that many of them. These people are loners in a meaningful sense, cores of fraud working on their own behalf. They don’t form networks with each other, for the most part: because they work towards their own aggrandizement, they have no reason to trust anyone else doing the same. I have yet to see evidence that the number of these people is increasing. They exist, they’re a problem, they’re important to watch out for. But they’re not a crisis, and they shouldn’t shift your default expectations of science.
The other, quite different, type of scientific fraud is fraud for a fee.
The cases this paper investigates seem to fall into this category. They are businesses, offering the raw material of academic credit (papers, co-authorship, citations, publication) for cash. They’re paper mills, of various sorts. These are, at least from an academic perspective, large organizations, with hundreds or thousands of customers and tens of suborned editors or scientists farming out their credibility. As the authors of this paper argue, fraudsters of this type are churning out more and more papers, potentially now fueled by AI, adding up to a still small, but non-negligible, proportion of scientific papers in total.
Compared to the first type of fraud, though, buying credit in this way doesn’t give very much power. As the paper describes, many of the papers churned out by paper mills don’t even go into relevant journals: for example, they mention “an article about roasting hazelnuts in a journal about HIV/AIDS care”. An article like that isn’t going to mislead the hazelnut roasting community, or the HIV/AIDS community. Indeed, that would be counter to its purpose. The paper isn’t intended to be read at all, and ideally gets ignored: it’s just supposed to inflate a number.
These numbers are most relevant in the developing world, and when push comes to shove, almost all of the buyers of these services identified by the authors of this paper come from there. In many developing countries, a combination of low trust and advice from economists leads to explicit point systems, where academics are paid or hired explicitly based on criteria like where and how often they publish or how they are cited. The more a country can trust people to vouch for each other without corruption, the less these kinds of incentives have purchase. Outside of the developing world, involvement in paper mills and the like generally seems to involve a much smaller number of people, and typically as sellers, not buyers: selling first-world credibility in exchange for fees from many developing-world applicants.
(The one reference I mentioned above is an interesting example of this: a system built out of points and low trust to recruit doctors from the developing world to the US, gamed by a small number of co-authorship brokers.)
This kind of fraud doesn’t influence science directly. Its perpetrators aren’t trying to get noticed, but to keep up a cushy scam. You don’t hear their conclusions in the press, other scientists don’t see their work. Instead, they siphon off resources: cannibalizing journals, flooding editors with mass-produced crap, and filling positions and slurping up science budgets in the countries that can least afford them. As they publish more and more, they shouldn’t affect your expectations of the credibility of science: any science you hear about will be either genuine, or fraud from the other category. But they do make the science you hear about harder and harder to do.
(The authors point out one exception: what about AI? If a company trains a large language model on the current internet, will its context windows be long enough to tell that that supposedly legitimate paper about hazelnuts is in an HIV/AIDS journal? If something gets said often enough, copied again and again in papers sold by a mill, will an AI trained on all these papers be convinced? Presumably, someone is being paid good money to figure out how to filter AI-generated slop from training data: can they filter paper mill fraud as well?)
It’s a shame that we have one term, scientific fraud, to deal with these two very different things. But it’s important to keep in mind that they are different. Fraud for power and fraud for money can have very different profiles, and offer very different risks. If you don’t trust a scientific result, it’s worth understanding what might be at play.







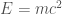 . In the mid-20th century these particle colliders were serious pieces of machinery, but still small enough to make industrial: now, there are so-called medical accelerators in many hospitals based on their designs. But current particle accelerators are a different beast, massive facilities built by international collaborations. This is the Energy Frontier.
. In the mid-20th century these particle colliders were serious pieces of machinery, but still small enough to make industrial: now, there are so-called medical accelerators in many hospitals based on their designs. But current particle accelerators are a different beast, massive facilities built by international collaborations. This is the Energy Frontier.