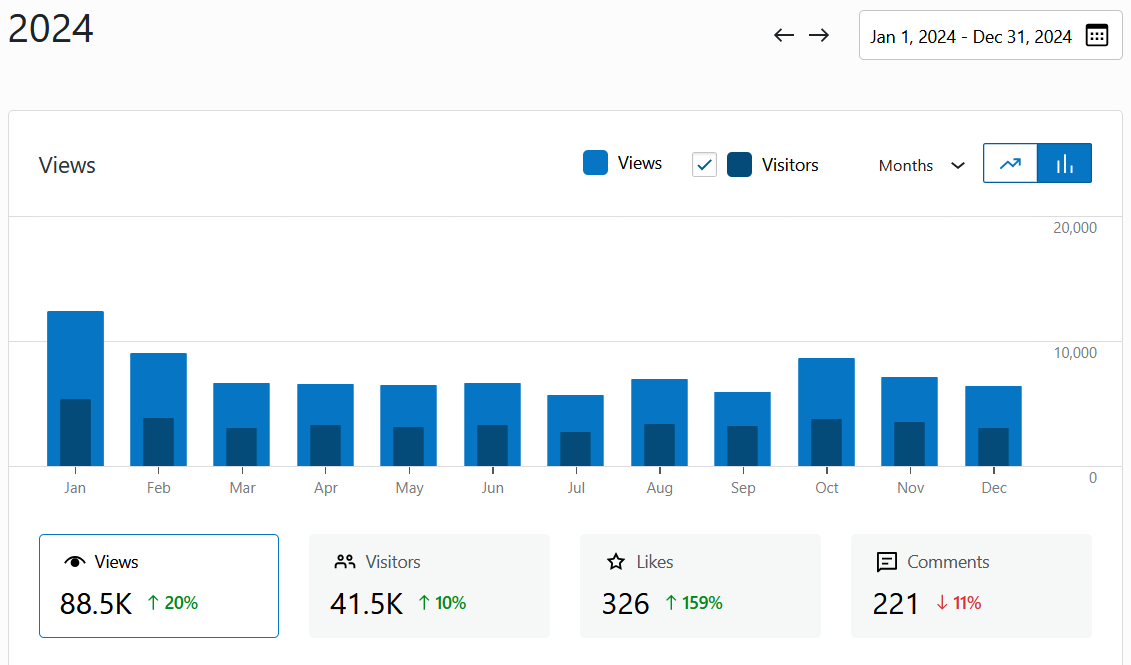
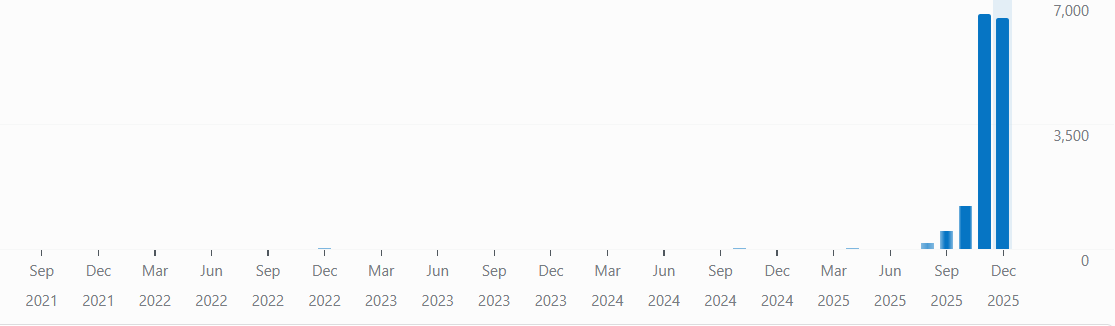
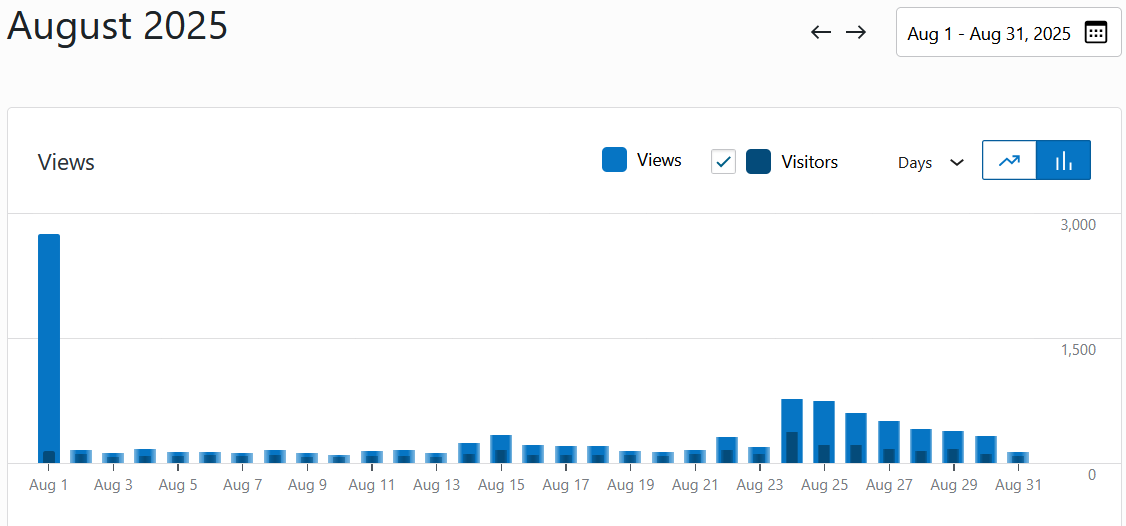
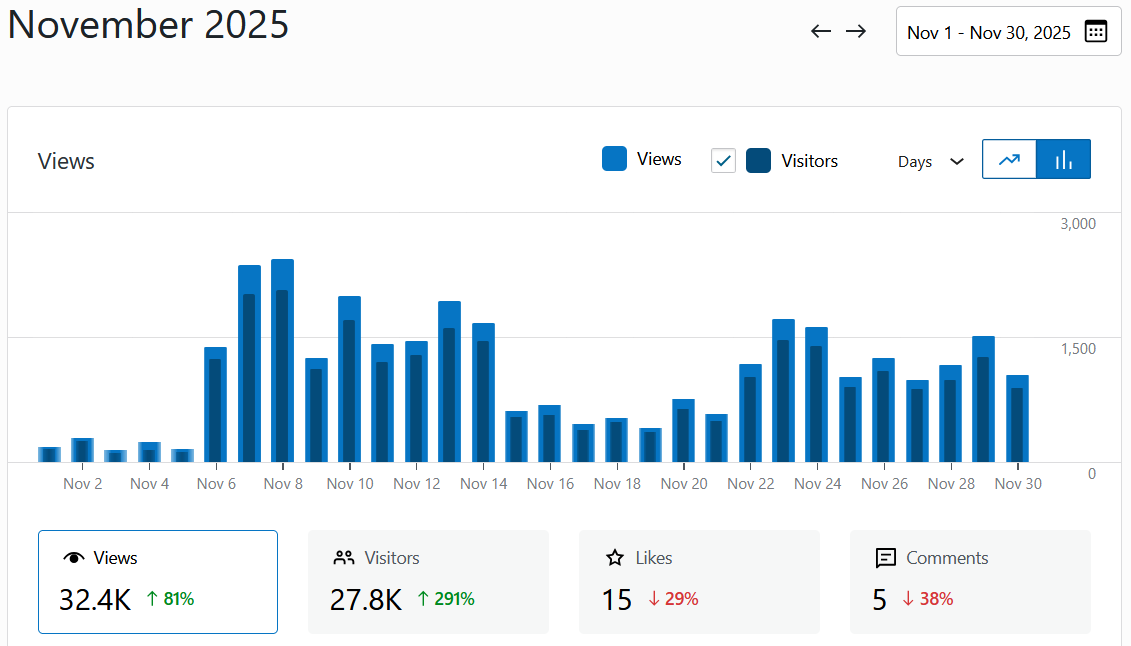
It’s there in every biography, and many interviews: the moment the scientist falls in love with an idea. It can be a kid watching ants in the backyard, a teen peering through a telescope, or an undergrad seeing a heart cell beat on a slide. It’s a story so common that it forms the heart of the public idea of a scientist: not just someone smart enough to understand the world, but someone passionate enough to dive in to their one particular area above all else. It’s easy to think of it as a kind of passion most people never get to experience.
And it does happen, sometimes. But it’s a lot less common than you’d think.
I first started to suspect this as a PhD student. In the US, getting accepted into a PhD program doesn’t guarantee you an advisor to work with. You have to impress a professor to get them to spend limited time and research funding on you. In practice, the result was the academic analog of the dating scene. Students looked for who they might have a chance with, based partly on interest but mostly on availability and luck and rapport, and some bounced off many potential mentors before finding one that would stick.
Then, for those who continued to postdoctoral positions, the same story happened all over again. Now, they were applying for jobs, looking for positions where they were qualified enough and might have some useful contacts, with interest into the specific research topic at best a distant third.
Working in the EU, I’ve seen the same patterns, but offset a bit. Students do a Master’s thesis, and the search for a mentor there is messy and arbitrary in similar ways. Then for a PhD, they apply for specific projects elsewhere, and as each project is its own funded position the same job search dynamics apply.
The picture only really clicked for me, though, when I started doing journalism.
Nowadays, I don’t do science, I interview people about it. The people I interview are by and large survivors: people who got through the process of applying again and again and now are sitting tight in an in-principle permanent position. They’re people with a lot of freedom to choose what to do.
And so I often ask for that reason, that passion, that scientific love at first sight moment: why do you study what you do? It’s a story that audiences love, and thus that editors love, it’s always a great way to begin a piece.
But surprisingly often, I get an unromantic answer. Why study this? Because it was available. Because in the Master’s, that professor taught the intro course. Because in college, their advisor had contacts with that lab to arrange a study project. Because that program accepted people from that country.
And I’ve noticed how even the romantic answers tend to be built on the unromantic ones. The professors who know how to weave a story, to self-promote and talk like a politician, they’ll be able to tell you about falling in love with something, sure. But if you read between the lines, you’ll notice where their anecdotes fall, how they trace a line through the same career steps that less adroit communicators admit were the real motivation.
There’s been times I’ve thought that my problem was a lack of passion, that I wasn’t in love the same way other scientists were in love. I’ve even felt guilty, that I took resources and positions from people who were. There is still some truth in that guilt, I don’t think I had the same passion for my science as most of my colleagues.
But I appreciate more now, that that passion is in part a story. We don’t choose our specialty, making some grand agentic move. Life chooses for us. And the romance comes in how you tell that story, after the fact.


 and
and  . In the research world, people are far more likely to run into calculations like this:
. In the research world, people are far more likely to run into calculations like this: