
I’m a theoretical physicist. That means I work with pencil and paper, or with my laptop, or at most with a computer cluster. I don’t have a lab, and even if I did I wouldn’t have any equipment to store there.
By contrast, most physicists (and most scientists in general) are experimentalists, the people who actually do experiments, actually work in labs, and actually use piles and piles of expensive equipment. Naturally, these two groups have very different ways of doing things, spawned by different requirements for their jobs. This leads to very different ways of talking. We theorists sometimes get confused by the quaint turns of phrase used by experimentalists, so I’ve put together this handy translation guide:
Lab: Kind of like an office, but has a bunch of big machines in it for some reason. Also, in some of them they don’t even drink coffee, some nonsense about toxic contaminants. I don’t know how they get any work done with all those test tubes all over the place.
PI: Not Private Investigator, but close! The Primary Investigator is the big cheese among the experimentalists, the one who owns all the big machines. All of the others must bow before him or her, even fellow professors must grovel if they want to use the PI’s expensive equipment. Naturally, this makes experimentalists very hierarchical, a sharp contrast to theorists who are obviously totally egalitarian.
Poster: Let me tell you a secret about experimentalists: there are a lot of them. Way more than there are theorists. So many, that if they all go to a conference it’s impossible for them all to give talks! That’s where posters come in: some of the experimentalists all stand in a room in front of rectangles of cardboard covered in charts, while the others walk around and ask questions. Traditionally, these posters are printed an hour before the conference, obviously for maximum freshness and not at all because of procrastination.
Group: Like our Institutes, but (because there are a lot of experimentalists) there isn’t just one per university and (because of the shared lab) they actually have something to talk about. This leads to regular group meetings, because when you’re using expensive equipment you actually need to show you’re doing something worthwhile with it.
IRB: For the medical and psychological folks, the Internal Review Board is there to tell you that, no, you can’t infect monkeys with flesh-eating bacteria just to see what happens. They’re also the people who ask you whether a grammatical change in your online survey will pose risks to pregnant women, which is clearly exactly as important. Theorists don’t have these, because numbers are an oppressed underclass with no rights to speak of. EHS (Environmental Health and Safety) fills a similar role for those who only oppress yeast and their own grad students.
Annual Meeting: Experimentalists tend to be part of big organizations like the American Physical Society. And that’s all well and good, occupies a space on the CV and so forth. What’s somewhat more baffling is their tendency to trust those organizations to run conferences. Generally these are massive affairs, with people from all sorts of sub-fields participating. This only works because experimentalists have the mysterious ability to walk into each other’s talks and actually understand what’s going on, even if the subject matter is very different from what they’re used to. Experts suggest this has something to do with actually studying real things in the real world, but this is a hypothesis at best.


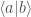 . What if you need to separate the two states,
. What if you need to separate the two states,  and
and 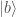 ?
? 






