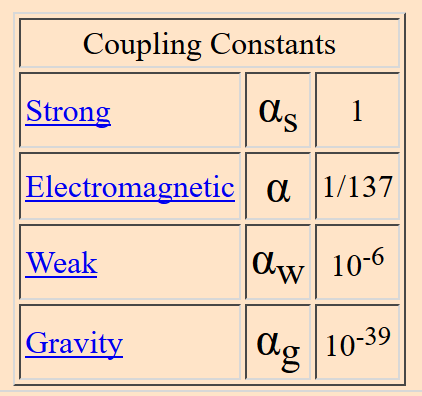
There’s a debate raging right now in particle physics, about whether and how to build the next big collider. CERN’s Future Circular Collider group has been studying different options, some more expensive and some less (Peter Woit has a nice summary of these here). This year, the European particle physics community will debate these proposals, deciding whether to include them in an updated European Strategy for Particle Physics. After that, it will be up to the various countries that are members of CERN to decide whether to fund the proposal. With the costs of the more expensive options hovering around $20 billion, this has led to substantial controversy.
I’m not going to offer an opinion here one way or another. Weighing this kind of thing requires knowing the alternatives: what else the European particle physics community might lobby for in the next few years, and once they decide, what other budget priorities each individual country has. I know almost nothing about either.
Instead of an opinion, I have an observation:
Imagine that primatologists had proposed a $20 billion primate center, able to observe gorillas in greater detail than ever before. The proposal might be criticized in any number of ways: there could be much cheaper ways to accomplish the same thing, the project might fail, it might be that we simply don’t care enough about primate behavior to spend $20 billion on it.
What you wouldn’t expect is the claim that a $20 billion primate center would teach us nothing new.
It probably wouldn’t teach us “$20 billion worth of science”, whatever that means. But a center like that would be guaranteed to discover something. That’s because we don’t expect primatologists’ theories to be exact. Even if gorillas behaved roughly as primatologists expected, the center would still see new behaviors, just as a consequence of looking at a new level of detail.
To pick a physics example, consider the gravitational wave telescope LIGO. Before their 2016 observation of two black holes merging, LIGO faced substantial criticism. After their initial experiments didn’t detect anything, many physicists thought that the project was doomed to fail: that it would never be sensitive enough to detect the faint signals of gravitational waves past the messy vibrations of everyday life on Earth.
When it finally worked, though, LIGO did teach us something new. Not the existence of gravitational waves, we already knew about them. Rather, LIGO taught us new things about the kinds of black holes that exist. LIGO observed much bigger black holes than astronomers expected, a surprise big enough that it left some people skeptical. Even if it hadn’t, though, we still would almost certainly observe something new: there’s no reason to expect astronomers to perfectly predict the size of the universe’s black holes.
Particle physics is different.
I don’t want to dismiss the work that goes in to collider physics (far too many people have dismissed it recently). Much, perhaps most, of the work on the LHC is dedicated not to detecting new particles, but to confirming and measuring the Standard Model. A new collider would bring heroic scientific effort. We’d learn revolutionary new things about how to build colliders, how to analyze data from colliders, and how to use the Standard Model to make predictions for colliders.
In the end, though, we expect those predictions to work. And not just to work reasonably well, but to work perfectly. While we might see something beyond the Standard Model, the default expectation is that we won’t, that after doing the experiments and analyzing the data and comparing to predictions we’ll get results that are statistically indistinguishable from an equation we can fit on a T-shirt. We’ll fix the constants on that T-shirt to an unprecedented level of precision, yes, but the form of the equation may well stay completely the same.
I don’t think there’s another field where that’s even an option. Nowhere else in all of science could we observe the world in unprecedented detail, capturing phenomena that had never been seen before…and end up perfectly matching our existing theory. There’s no other science where anyone would even expect that to happen.
That makes the argument here different from any argument we’ve faced before. It forces people to consider their deep priorities, to think not just about the best way to carry out this test or that but about what science is supposed to be for. I don’t think there are any easy answers. We’re in what may well be a genuinely new situation, and we have to figure out how to navigate it together.
Postscript: I still don’t want to give an opinion, but given that I didn’t have room for this above let me give a fragment of an opinion: Higgs triple couplings!!!