Somewhat overshadowed by the very picturesque Alps
Amplitudes keeps on growing. In 2019, we had 175 participants. We were on Zoom in 2020 and 2021, with many more participants, but that probably shouldn’t count. In Prague last year we had 222. This year, I’ve been told we have even more, something like 250 participants (the list online is bigger, but includes people joining on Zoom). We’ve grown due to new students, but also new collaborations: people from adjacent fields who find the work interesting enough to join along. This year we have mathematicians talking about D-modules, bootstrappers finding new ways to get at amplitudes in string theory, beyond-the-standard-model theorists talking about effective field theories, and cosmologists talking about the large-scale structure of the universe.
The talks have been great, from clear discussions of earlier results to fresh-off-the-presses developments, plenty of work in progress, and even one talk where the speaker’s opinion changed during the coffee break. As we’re at CERN, there’s also a through-line about the future of particle physics, with a chat between Nima Arkani-Hamed and the experimentalist Beate Heinemann on Tuesday and a talk by Michelangelo Mangano about the meaning of “new physics” on Thursday.
I haven’t had a ton of time to write, I keep getting distracted by good discussions! As such, I’ll do my usual thing, and say a bit more about specific talks in next week’s post.
Reading that, you might ask whether we can do better. What about a model-independent measurement of the age of the universe?
As intuitive as it might seem, we can’t actually do that. In fact, if we’re really strict about it, we can’t get a model-independent measurement of anything at all. Everything is based on a model.
Imagine stepping on your bathroom scale, getting a mass in kilograms. The number it gives you seems as objective as anything. But to get that number, you have to trust that a number of models are true. You have to model gravity, to assume that the scale’s measurement of your weight gives you the right mass based on the Earth’s surface gravity being approximately constant. You have to model the circuits and sensors in the scale, and be confident that you understand how they’re supposed to work. You have to model people: to assume that the company that made the scale tested it accurately, and that the people who sold it to you didn’t lie about where it came from. And finally, you have to model error: you know that the scale can’t possibly give you your exact weight, so you need a rough idea of just how far off it can reasonably be.
Everything we know is like this. Every measurement in science builds on past science, on our understanding of our measuring equipment and our trust in others. Everything in our daily lives comes through a network of assumptions about the world around us. Everything we perceive is filtered through instincts, our understanding of our own senses and knowledge of when they do and don’t trick us.
Ok, but when I say that the age of the universe is model-dependent, I don’t really mean it like that, right?
Everything we know is model-dependent, but only some model-dependence is worth worrying about. Your knowledge of your bathroom scale comes from centuries-old physics of gravity, widely-applied principles of electronics, and a trust in the function of basic products that serves you well in every other aspect of your life. The models that knowledge depends on aren’t really in question, especially not when you just want to measure your weight.
Some measurements we make in physics are like this too. When the experimental collaborations at the LHC measured the Higgs mass, they were doing something far from routine. But the models they based that measurement on, models of particle physics and particle detector electronics and their own computer code, are still so well-tested that it mostly doesn’t make sense to think of this as a model-dependent measurement. If we’re questioning the Higgs mass, it’s only because we’re questioning something much bigger.
The age of the universe, though, is trickier. Our most precise measurements are based on a specific model: we estimate what the universe is made of and how fast it’s expanding, plug it into our model of how the universe changes over time, and get an estimate for the age. You might suggest that we should just look out into the universe and find the oldest star, but that’s model-dependent too. Stars don’t have rings like trees. Instead, to estimate the age of a star we have to have some model for what kind of light it emits, and for how that light has changed over the history of the universe before it reached us.
These models are not quite as well-established as the models behind particle physics, let alone those behind your bathroom scale. Our models of stars are pretty good, applied to many types of stars in many different galaxies, but they do involve big, complicated systems involving many types of extreme and difficult to estimate physics. Star models get revised all the time, usually in minor ways but occasionally in more dramatic ones. Meanwhile, our model of the whole universe is powerful, but by its very nature much less-tested. We can test it on observations of the whole universe today, or on observations of the whole universe in the past (like the cosmic microwave background). And it works well for these, better than any other model. But it’s not inconceivable, not unrealistic, and above all not out of context, that another model could take its place. And if it did, many of the model-dependent measurements we’ve based on it will have to change.
So that’s why, while everything we know is model-dependent, some are model-dependent in a more important way. Some things, even if we feel they have solid backing, may well turn out to be wrong, in a way that we have reason to take seriously. The age of the universe is pretty well-established as these things go, but it still is one of those types of things, where there is enough doubt in our model that we can’t just take the measurement at face value.
“The news doesn’t come from a telescope, though, or a new observation of the sky. Instead, it comes from this press release from the University of Ottawa: “Reinventing cosmology: uOttawa research puts age of universe at 26.7 — not 13.7 — billion years”.
(If you look, you’ll find many websites copying this press release almost word-for-word. This is pretty common in science news, where some websites simply aggregate press releases and others base most of their science news on them rather than paying enough for actual journalism.)
The press release, in turn, is talking about a theory, not an observation. The theorist, Rajendra Gupta, was motivated by examples like the early galaxies observed by JWST and the Methuselah star. Since the 13.8 billion year age of the universe is based on a mathematical model, he tried to find a different mathematical model that led to an older universe. Eventually, by hypothesizing what seems like every unproven physics effect he could think of, he found one that gives a different estimate, 26.7 billion. He probably wasn’t the first person to do this, because coming up with different models to explain odd observations is a standard thing cosmologists do all the time, and until one of the models is shown to explain a wider range of observations (because our best theories explain a lot, so they’re hard to replace), they’re just treated as speculation, not newsworthy science.
This is a pretty clear case of hype, and as such most of the discussion has been about what went wrong. Should we blame the theorist? The university? The journalists? Elon Musk?
Rather than blame, I think it’s more productive to offer advice. And in this situation, the person I think could use some advice is the person who wrote the press release.
So suppose you work for a university, writing their press releases. One day, you hear that one of your professors has done something very cool, something worthy of a press release: they’ve found a new estimate for the age of the universe. What do you do?
One thing you absolutely shouldn’t do is question the science. That just isn’t your job, and even if it were you don’t have the expertise to do that. Anyone who’s hoping that you will only write articles about good science and not bad science is being unrealistic, that’s just not an option.
If you can’t be more accurate, though, you can still be more precise. You can write your article, and in particular your headline, so that you express what you do know as clearly and specifically as possible.
(I’m assuming here you write your own headlines. This is not normal in journalism, where most headlines are written by an editor, not by the writer of a piece. But university press offices are small enough that I’m assuming, perhaps incorrectly, that you can choose how to title your piece.)
Let’s take a look at the title, “Reinventing cosmology: uOttawa research puts age of universe at 26.7 — not 13.7 — billion years”, and see if we can make some small changes to improve it.
One very general word in that title is “research”. Lots of people do research: astronomers do research when they collect observations, theorists do research when they make new models. If you say “research”, some people will think you’re reporting a new observation, a new measurement that gives a radically different age for the universe.
But you know that’s not true, it’s not what the scientist you’re talking to is telling you. So to avoid the misunderstanding, you can get a bit more specific, and replace the word “research” with a more precise one: “Reinventing cosmology: uOttawa theory puts age of universe at 26.7 — not 13.7 — billion years”.
“Theory” is just as familiar a word as “research”. You won’t lose clicks, you won’t confuse people. But now, you’ve closed off a big potential misunderstanding. By a small shift, you’ve gotten a lot clearer. And you didn’t need to question the science to do it!
You can do more small shifts, if you understand a bit more of the science. “Puts” is kind of ambiguous: a theory could put an age somewhere because it computes it from first principles, or because it dialed some parameter to get there. Here, the theory was intentionally chosen to give an older universe, so the title should hint at this in some way. Instead of “puts”, then, you can use “allows”: “Reinventing cosmology: uOttawa theory allows age of universe to be 26.7 — not 13.7 — billion years”.
These kinds of little tricks can be very helpful. If you’re trying to avoid being misunderstood, then it’s good to be as specific as you can, given what you understand. If you do it carefully, you don’t have to question your scientists’ ideas or downplay their contributions. You can do your job, promote your scientists, and still contribute to responsible journalism.
If you follow astronomers on twitter, you may have heard some rumblings. For the last week or so, a few big collaborations have been hyping up an announcement of “something big”.
Those who knew who those collaborations were could guess the topic. Everyone else found out on Wednesday, when the alphabet soup of NANOGrav, EPTA, PPTA, CPTA, and InPTA announced detection of a gravitational wave background.
These guys
Who are these guys? And what have they found?
You’ll notice the letters “PTA” showing up again and again here. PTA doesn’t stand for Parent-Teacher Association, but for Pulsar Timing Array. Pulsar timing arrays keep track of pulsars, special neutron stars that spin around, shooting out jets of light. The ones studied by PTAs spin so regularly that we can use them as a kind of cosmic clock, counting time by when their beams hit our telescopes. They’re so regular that, if we see them vary, the best explanation isn’t that their spinning has changed: it’s that space-time itself has.
Because of that, we can use pulsar timing arrays to detect subtle shifts in space and time, ripples in the fabric of the universe caused by enormous gravitational waves. That’s what all these collaborations are for: the Indian Pulsar Timing Array (InPTA), the Chinese Pulsar Timing Array (CPTA), the Parkes Pulsar Timing Array (PPTA), the European Pulsar Timing Array (EPTA), and the North American Nanohertz Observatory for Gravitational Waves (NANOGrav).
For a nice explanation of what they saw, read this twitter thread by Katie Mack, who unlike me is actually an astronomer. NANOGrav, in typical North American fashion, is talking the loudest about it, but in this case they kind of deserve it. They have the most data, fifteen years of measurements, letting them make the clearest case that they are actually seeing evidence of gravitational waves. (And not, as an earlier measurement of theirs saw, Jupiter.)
We’ve seen evidence of gravitational waves before of course, most recently from the gravitational wave observatories LIGO and VIRGO. LIGO and VIRGO could pinpoint their results to colliding black holes and neutrons stars, estimating where they were and how massive. The pulsar timing arrays can’t quite do that yet, even with fifteen years of data. They expect that the waves they are seeing come from colliding black holes as well, but much larger ones: with pulsars spread over a galaxy, the effects they detect are from black holes big enough to be galactic cores. Rather than one at a time, they would see a chorus of many at once, a gravitational wave background (though not to be confused with a cosmic gravitational wave background: this would be from black holes close to the present day, not from the origin of the universe). If it is this background, then they’re seeing a bit more of the super-massive black holes than people expected. But for now, they’re not sure: they can show they’re seeing gravitational waves, but so far not much more.
With that in mind, it’s best to view the result, impressive as it is, as a proof of principle. Much as LIGO showed, not that gravitational waves exist at all, but that it is possible for us to detect them, these pulsar timing arrays have shown that it is possible to detect the gravitational wave background on these vast scales. As the different arrays pool their data and gather more, the technique will become more and more useful. We’ll start learning new things about the life-cycles of black holes and galaxies, about the shape of the universe, and maybe if we’re lucky some fundamental physics too. We’ve opened up a new window, making sure it’s bright enough we can see. Now we can sit back, and watch the universe.
Nowadays, we have telescopes that detect not just light, but gravitational waves. We’ve already learned quite a bit about astrophysics from these telescopes. They observe ripples coming from colliding black holes, giving us a better idea of what kinds of black holes exist in the universe. But the coolest thing a gravitational wave telescope could discover is something that hasn’t been seen yet: a cosmic string.
This art is from an article in Symmetry magazine which is, as far as I can tell, not actually about cosmic strings.
You might have heard of cosmic strings, but unless you’re a physicist you probably don’t know much about them. They’re a prediction, coming from cosmology, of giant string-like objects floating out in space.
That might sound like it has something to do with string theory, but it doesn’t actually have to, you can have these things without any string theory at all. Instead, you might have heard that cosmic strings are some kind of “cracks” or “wrinkles” in space-time. Some articles describe this as like what happens when ice freezes, cracks forming as water settles into a crystal.
That description, in terms of ice forming cracks between crystals, is great…if you’re a physicist who already knows how ice forms cracks between crystals. If you’re not, I’m guessing reading those kinds of explanations isn’t helpful. I’m guessing you’re still wondering why there ought to be any giant strings floating in space.
The real explanation has to do with a type of mathematical gadget physicists use, called a scalar field. You can think of a scalar field as described by a number, like a temperature, that can vary in space and time. The field carries potential energy, and that energy depends on what the scalar field’s “number” is. Left alone, the field settles into a situation with as little potential energy as it can, like a ball rolling down a hill. That situation is one of the field’s default values, something we call a “vacuum” value. Changing the field away from its vacuum value can take a lot of energy. The Higgs boson is one example of a scalar field. Its vacuum value is the value it has in day to day life. In order to make a detectable Higgs boson at the Large Hadron Collider, they needed to change the field away from its vacuum value, and that took a lot of energy.
In the very early universe, almost back at the Big Bang, the world was famously in a hot dense state. That hot dense state meant that there was a lot of energy to go around, so scalar fields could vary far from their vacuum values, pretty much randomly. As the universe expanded and cooled, there was less and less energy available for these fields, and they started to settle down.
Now, the thing about these default, “vacuum” values of a scalar field is that there doesn’t have to be just one of them. Depending on what kind of mathematical function the field’s potential energy is, there could be several different possibilities each with equal energy.
Let’s imagine a simple example, of a field with two vacuum values: +1 and -1. As the universe cooled down, some parts of the universe would end up with that scalar field number equal to +1, and some to -1. But what happens in between?
The scalar field can’t just jump from -1 to +1, that’s not allowed in physics. It has to pass through 0 in between. But, unlike -1 and +1, 0 is not a vacuum value. When the scalar field number is equal to 0, the field has more energy than it does when it’s equal to -1 or +1. Usually, a lot more energy.
That means the region of scalar field number 0 can’t spread very far: the further it spreads, the more energy it takes to keep it that way. On the other hand, the region can’t vanish altogether: something needs to happen to transition between the numbers -1 and +1.
The thing that happens is called a domain wall. A domain wall is a thin sheet, as thin as it can physically be, where the scalar field doesn’t take its vacuum value. You can roughly think of it as made up of the scalar field, a churning zone of the kind of bosons the LHC was trying to detect.
This sheet still has a lot of energy, bound up in the unusual value of the scalar field, like an LHC collision in every proton-sized chunk. As such, like any object with a lot of energy, it has a gravitational field. For a domain wall, the effect of this gravity would be very very dramatic: so dramatic, that we’re pretty sure they’re incredibly rare. If they were at all common, we would have seen evidence of them long before now!
Ok, I’ve shown you a wall, that’s weird, sure. What does that have to do with cosmic strings?
The number representing a scalar field doesn’t have to be a real number: it can be imaginary instead, or even complex. Now I’d like you to imagine a field with vacuum values on the unit circle, in the complex plane. That means that +1 and -1 are still vacuum values, but so are , and , and everything else you can write as . However, 0 is still not a vacuum value. Neither is, for example, .
With vacuum values like this, you can’t form domain walls. You can make a path between -1 and +1 that only goes through the unit circle, through for example. The field will be at its vacuum value throughout, taking no extra energy.
However, imagine the different regions form a circle. In the picture above, suppose that the blue area at the bottom is at vacuum value -1 and red is at +1. You might have in the green region, and in the purple region, covering the whole circle smoothly as you go around.
Now, think about what happens in the middle of the circle. On one side of the circle, you have -1. On the other, +1. (Or, on one side , on the other, ). No matter what, different sides of the circle are not allowed to be next to each other, you can’t just jump between them. So in the very middle of the circle, something else has to happen.
Once again, that something else is a field that goes away from its vacuum value, that passes through 0. Once again, that takes a lot of energy, so it occupies as little space as possible. But now, that space isn’t a giant wall. Instead, it’s a squiggly line: a cosmic string.
Cosmic strings don’t have as dramatic a gravitational effect as domain walls. That means they might not be super-rare. There might be some we haven’t seen yet. And if we do see them, it could be because they wiggle space and time, making gravitational waves.
Cosmic strings don’t require string theory, they come from a much more basic gadget, scalar fields. We know there is one quite important scalar field, the Higgs field. The Higgs vacuum values aren’t like +1 and -1, or like the unit circle, though, so the Higgs by itself won’t make domain walls or cosmic strings. But there are a lot of proposals for scalar fields, things we haven’t discovered but that physicists think might answer lingering questions in particle physics, and some of those could have the right kind of vacuum values to give us cosmic strings. Thus, if we manage to detect cosmic strings, we could learn something about one of those lingering questions.
I’ve never met someone who believed the Earth was flat. I’ve met a few who believed it was six thousand years old, but not many. Occasionally, I run into crackpots who rail against relativity or quantum mechanics, or more recent discoveries like quarks or the Higgs. But for one conclusion of modern physics, the doubters are common. For this one idea, the average person may not insist that the physicists are wrong, but they’ll usually roll their eyes a little bit, ask the occasional “really?”
That idea is dark matter.
For the average person, dark matter doesn’t sound like normal, responsible science. It sounds like cheating. Scientists try to explain the universe, using stars and planets and gravity, and eventually they notice the equations don’t work, so they just introduce some new matter nobody can detect. It’s as if a budget didn’t add up, so the accountant just introduced some “dark expenses” to hide the problem.
Part of what’s going on here is that fundamental physics, unlike other fields, doesn’t have to reduce to something else. An accountant has to explain the world in terms of transfers of money, a chemist in terms of atoms and molecules. A physicist has to explain the world in terms of math, with no more restrictions than that. Whatever the “base level” of another field is, physics can, and must, go deeper.
But that doesn’t explain everything. Physics may have to explain things in terms of math, but we shouldn’t just invent new math whenever we feel like it. Surely, we should prefer explanations in terms of things we know to explanations in terms of things we don’t know. The question then becomes, what justifies the preference? And when do we get to break it?
Imagine you’re camping in your backyard. You’ve brought a pack of jumbo marshmallows. You wake up to find a hole torn in the bag, a few marshmallows strewn on a trail into the bushes, the rest gone. You’re tempted to imagine a new species of ant, with enormous jaws capable of ripping open plastic and hauling the marshmallows away. Then you remember your brother likes marshmallows, and it’s probably his fault.
Now imagine instead you’re camping in the Amazon rainforest. Suddenly, the ant explanation makes sense. You may not have a particular species of ants in mind, but you know the rainforest is full of new species no-one has yet discovered. And you’re pretty sure your brother couldn’t have flown to your campsite in the middle of the night and stolen your marshmallows.
We do have a preference against introducing new types of “stuff”, like new species of ants or new particles. We have that preference because these new types of stuff are unlikely, based on our current knowledge. We don’t expect new species of ants in our backyards, because we think we have a pretty good idea of what kinds of ants exist, and we think a marshmallow-stealing brother is more likely. That preference gets dropped, however, based on the strength of the evidence. If it’s very unlikely our brother stole the marshmallows, and if we’re somewhere our knowledge of ants is weak, then the marshmallow-stealing ants are more likely.
Dark matter is a massive leap. It’s not a massive leap because we can’t see it, but simply because it involves new particles, particles not in our Standard Model of particle physics. (Or, for the MOND-ish fans, new fields not present in Einstein’s theory of general relativity.) It’s hard to justify physics beyond the Standard Model, and our standards for justifying it are in general very high: we need very precise experiments to conclude that the Standard Model is well and truly broken.
For dark matter, we keep those standards. The evidence for some kind of dark matter, that there is something that can’t be explained by just the Standard Model and Einstein’s gravity, is at this point very strong. Far from a vague force that appears everywhere, we can map dark matter’s location, systematically describe its effect on the motion of galaxies to clusters of galaxies to the early history of the universe. We’ve checked if there’s something we’ve left out, if black holes or unseen planets might cover it, and they can’t. It’s still possible we’ve missed something, just like it’s possible your brother flew to the Amazon to steal your marshmallows, but it’s less likely than the alternatives.
Also, much like ants in the rainforest, we don’t know every type of particle. We know there are things we’re missing: new types of neutrinos, or new particles to explain quantum gravity. These don’t have to have anything to do with dark matter, they might be totally unrelated. But they do show that we should expect, sometimes, to run into particles we don’t already know about. We shouldn’t expect that we already know all the particles.
If physicists did what the cartoons suggest, it really would be cheating. If we proposed dark matter because our equations didn’t match up, and stopped checking, we’d be no better than an accountant adding “dark money” to a budget. But we didn’t do that. When we argue that dark matter exists, it’s because we’ve actually tried to put together the evidence, because we’ve weighed it against the preference to stick with the Standard Model and found the evidence tips the scales. The instinct to call it cheating is a good instinct, one you should cultivate. But here, it’s an instinct physicists have already taken into account.
There’s a saying in physics, attributed to the famous genius John von Neumann: “With four parameters I can fit an elephant, and with five I can make him wiggle his trunk.”
Say you want to model something, like some surprising data from a particle collider. You start with some free parameters: numbers in your model that aren’t decided yet. You then decide those numbers, “fixing” them based on the data you want to model. Your goal is for your model not only to match the data, but to predict something you haven’t yet measured. Then you can go out and check, and see if your model works.
The more free parameters you have in your model, the easier this can go wrong. More free parameters make it easier to fit your data, but that’s because they make it easier to fit any data. Your model ends up not just matching the physics, but matching the mistakes as well: the small errors that crop up in any experiment. A model like that may look like it’s a great fit to the data, but its predictions will almost all be wrong. It wasn’t just fit, it was overfit.
We have statistical tools that tell us when to worry about overfitting, when we should be impressed by a model and when it has too many parameters. We don’t actually use these tools correctly, but they still give us a hint of what we actually want to know, namely, whether our model will make the right predictions. In a sense, these tools form the mathematical basis for Occam’s Razor, the idea that the best explanation is often the simplest one, and Occam’s Razor is a critical part of how we do science.
So, did you know machine learning was just modeling data?
All of the much-hyped recent advances in artificial intelligence, GPT and Stable Diffusion and all those folks, at heart they’re all doing this kind of thing. They start out with a model (with a lot more than five parameters, arranged in complicated layers…), then use data to fix the free parameters. Unlike most of the models physicists use, they can’t perfectly fix these numbers: there are too many of them, so they have to approximate. They then test their model on new data, and hope it still works.
Increasingly, it does, and impressively well, so well that the average person probably doesn’t realize this is what it’s doing. When you ask one of these AIs to make an image for you, what you’re doing is asking what image the model predicts would show up captioned with your text. It’s the same sort of thing as asking an economist what their model predicts the unemployment rate will be when inflation goes up. The machine learning model is just way, way more complicated.
As a physicist, the first time I heard about this, I had von Neumann’s quote in the back of my head. Yes, these machines are dealing with a lot more data, from a much more complicated reality. They literally are trying to fit elephants, even elephants wiggling their trunks. Still, the sheer number of parameters seemed fishy here. And for a little bit things seemed even more fishy, when I learned about double descent.
Suppose you start increasing the number of parameters in your model. Initially, your model gets better and better. Your predictions have less and less error, your error descends. Eventually, though, the error increases again: you have too many parameters so you’re over-fitting, and your model is capturing accidents in your data, not reality.
In machine learning, weirdly, this is often not the end of the story. Sometimes, your prediction error rises, only to fall once more, in a double descent.
For a while, I found this deeply disturbing. The idea that you can fit your data, start overfitting, and then keep overfitting, and somehow end up safe in the end, was terrifying. The way some of the popular accounts described it, like you were just overfitting more and more and that was fine, was baffling, especially when they seemed to predict that you could keep adding parameters, keep fitting tinier and tinier fleas on the elephant’s trunk, and your predictions would never start going wrong. It would be the death of Occam’s Razor as we know it, more complicated explanations beating simpler ones off to infinity.
Luckily, that’s not what happens. And after talking to a bunch of people, I think I finally understand this enough to say something about it here.
The right way to think about double descent is as overfitting prematurely. You do still expect your error to eventually go up: your model won’t be perfect forever, at some point you will really overfit. It might take a long time, though: machine learning people are trying to model very complicated things, like human behavior, with giant piles of data, so very complicated models may often be entirely appropriate. In the meantime, due to a bad choice of model, you can accidentally overfit early. You will eventually overcome this, pushing past with more parameters into a model that works again, but for a little while you might convince yourself, wrongly, that you have nothing more to learn.
So Occam’s Razor still holds, but with a twist. The best model is simple enough, but no simpler. And if you’re not careful enough, you can convince yourself that a too-simple model is as complicated as you can get.
Image from Astral Codex Ten
I was reminded of all this recently by somearticles by Sabine Hossenfelder.
Hossenfelder is a critic of mainstream fundamental physics. The articles were her restating a point she’s made many times before, including in (at least) one of her books. She thinks the people who propose new particles and try to search for them are wasting time, and the experiments motivated by those particles are wasting money. She’s motivated by something like Occam’s Razor, the need to stick to the simplest possible model that fits the evidence. In her view, the simplest models are those in which we don’t detect any more new particles any time soon, so those are the models she thinks we should stick with.
I tend to disagree with Hossenfelder. Here, I was oddly conflicted. In some of her examples, it seemed like she had a legitimate point. Others seemed like she missed the mark entirely.
Talk to most astrophysicists, and they’ll tell you dark matter is settled science. Indeed, there is a huge amount of evidence that something exists out there in the universe that we can’t see. It distorts the way galaxies rotate, lenses light with its gravity, and wiggled the early universe in pretty much the way you’d expect matter to.
What isn’t settled is whether that “something” interacts with anything else. It has to interact with gravity, of course, but everything else is in some sense “optional”. Astroparticle physicists use satellites to search for clues that dark matter has some other interactions: perhaps it is unstable, sometimes releasing tiny signals of light. If it did, it might solve other problems as well.
Hossenfelder thinks this is bunk (in part because she thinks those other problems are bunk). I kind of do too, though perhaps for a more general reason: I don’t think nature owes us an easy explanation. Dark matter isn’t obligated to solve any of our other problems, it just has to be dark matter. That seems in some sense like the simplest explanation, the one demanded by Occam’s Razor.
At the same time, I disagree with her substantially more on collider physics. At the Large Hadron Collider so far, all of the data is reasonably compatible with the Standard Model, our roughly half-century old theory of particle physics. Collider physicists search that data for subtle deviations, one of which might point to a general discrepancy, a hint of something beyond the Standard Model.
While my intuitions say that the simplest dark matter is completely dark, they don’t say that the simplest particle physics is the Standard Model. Back when the Standard Model was proposed, people might have said it was exceptionally simple because it had a property called “renormalizability”, but these days we view that as less important. Physicists like Ken Wilson and Steven Weinberg taught us to view theories as a kind of series of corrections, like a Taylor series in calculus. Each correction encodes new, rarer ways that particles can interact. A renormalizable theory is just the first term in this series. The higher terms might be zero, but they might not. We even know that some terms cannot be zero, because gravity is not renormalizable.
The two cases on the surface don’t seem that different. Dark matter might have zero interactions besides gravity, but it might have other interactions. The Standard Model might have zero corrections, but it might have nonzero corrections. But for some reason, my intuition treats the two differently: I would find it completely reasonable for dark matter to have no extra interactions, but very strange for the Standard Model to have no corrections.
I think part of where my intuition comes from here is my experience with other theories.
One example is a toy model called sine-Gordon theory. In sine-Gordon theory, this Taylor series of corrections is a very familiar Taylor series: the sine function! If you go correction by correction, you’ll see new interactions and more new interactions. But if you actually add them all up, something surprising happens. Sine-Gordon turns out to be a special theory, one with “no particle production”: unlike in normal particle physics, in sine-Gordon particles can neither be created nor destroyed. You would never know this if you did not add up all of the corrections.
String theory itself is another example. In string theory, elementary particles are replaced by strings, but you can think of that stringy behavior as a series of corrections on top of ordinary particles. Once again, you can try adding these things up correction by correction, but once again the “magic” doesn’t happen until the end. Only in the full series does string theory “do its thing”, and fix some of the big problems of quantum gravity.
If the real world really is a theory like this, then I think we have to worry about something like double descent.
Remember, double descent happens when our models can prematurely get worse before getting better. This can happen if the real thing we’re trying to model is very different from the model we’re using, like the example in this explainer that tries to use straight lines to match a curve. If we think a model is simpler because it puts fewer corrections on top of the Standard Model, then we may end up rejecting a reality with infinite corrections, a Taylor series that happens to add up to something quite nice. Occam’s Razor stops helping us if we can’t tell which models are really the simple ones.
The problem here is that every notion of “simple” we can appeal to here is aesthetic, a choice based on what makes the math look nicer. Other sciences don’t have this problem. When a biologist or a chemist wants to look for the simplest model, they look for a model with fewer organisms, fewer reactions…in the end, fewer atoms and molecules, fewer of the building-blocks given to those fields by physics. Fundamental physics can’t do this: we build our theories up from mathematics, and mathematics only demands that we be consistent. We can call theories simpler because we can write them in a simple way (but we could write them in a different way too). Or we can call them simpler because they look more like toy models we’ve worked with before (but those toy models are just a tiny sample of all the theories that are possible). We don’t have a standard of simplicity that is actually reliable.
From the Wikipedia page for dark matter halos
There is one other way out of this pickle. A theory that is easier to write down is under no obligation to be true. But it is more likely to be useful. Even if the real world is ultimately described by some giant pile of mathematical parameters, if a simple theory is good enough for the engineers then it’s a better theory to aim for: a useful theory that makes peoples’ lives better.
I kind of get the feeling Hossenfelder would make this objection. I’ve seen her argue on twitter that scientists should always be able to say what their research is good for, and her Guardian article has this suggestive sentence: “However, we do not know that dark matter is indeed made of particles; and even if it is, to explain astrophysical observations one does not need to know details of the particles’ behaviour.”
Ok yes, to explain astrophysical observations one doesn’t need to know the details of dark matter particles’ behavior. But taking a step back, one doesn’t actually need to explain astrophysical observations at all.
Astrophysics and particle physics are not engineering problems. Nobody out there is trying to steer a spacecraft all the way across a galaxy, navigating the distribution of dark matter, or creating new universes and trying to make sure they go just right. Even if we might do these things some day, it will be so far in the future that our attempts to understand them won’t just be quaint: they will likely be actively damaging, confusing old research in dead languages that the field will be better off ignoring to start from scratch.
Because of that, usefulness is also not a meaningful guide. It cannot tell you which theories are more simple, which to favor with Occam’s Razor.
Hossenfelder’s highest-profile recent work falls afoul of one or the other of her principles. Her work on the foundations of quantum mechanics could genuinely be useful, but there’s no reason aside from claims of philosophical beauty to expect it to be true. Her work on modeling dark matter is at least directly motivated by data, but is guaranteed to not be useful.
I’m not pointing this out to call Hossenfelder a hypocrite, as some sort of ad hominem or tu quoque. I’m pointing this out because I don’t think it’s possible to do fundamental physics today without falling afoul of these principles. If you want to hold out hope that your work is useful, you don’t have a great reason besides a love of pretty math: otherwise, anything useful would have been discovered long ago. If you just try to model existing data as best you can, then you’re making a model for events far away or locked in high-energy particle colliders, a model no-one else besides other physicists will ever use.
I don’t know the way through this. I think if you need to take Occam’s Razor seriously, to build on the same foundations that work in every other scientific field…then you should stop doing fundamental physics. You won’t be able to make it work. If you still need to do it, if you can’t give up the sub-field, then you should justify it on building capabilities, on the kind of “practice” Hossenfelder also dismisses in her Guardian piece.
We don’t have a solid foundation, a reliable notion of what is simple and what isn’t. We have guesses and personal opinions. And until some experiment uncovers some blinding flash of new useful meaningful magic…I don’t think we can do any better than that.
During the pandemic, some conferences went online. Others went dormant.
Everysummer before the pandemic, the Niels Bohr International Academy hosted a conference called Current Themes in High Energy Physics and Cosmology. Current Themes is a small, cozy conference, a gathering of close friends some of whom happen to have Nobel prizes. Holding it online would be almost missing the point.
A particularly special Current Themes means some unusually special guests. Our guests are usually pretty special already (Gerard t’Hooft and David Gross are regulars, to just name the Nobelists), but this year we also had Alexander Polyakov. Polyakov’s talk had a magical air to it. In a quiet voice, broken by an impish grin when he surprised us with a joke, Polyakov began to lay out five unsolved problems he considered interesting. In the end, he only had time to present one, related to turbulence: when Gross asked him to name the remaining four, the second included a term most of us didn’t recognize (striction, known in a magnetic context and which he wanted to explore gravitationally), so the discussion hung while he defined that and we never did learn what the other three problems were.
At the big 100th anniversary celebration earlier in the spring, the Institute awarded a few years worth of its Niels Bohr Institute Medal of Honor. One of the recipients, Paul Steinhardt, couldn’t make it then, so he got his medal now. After the obligatory publicity photos were taken, Steinhardt entertained us all with a colloquium about his work on quasicrystals, including the many adventures involved in finding the first example “in the wild”. I can’t do the story justice in a short blog post, but if you won’t have the opportunity to watch him speak about it then I hear his book is good.
An anniversary conference should have some historical elements as well. For this one, these were ably provided by David Broadhurst, who gave an after-dinner speech cataloguing things he liked about Bohr. Some was based on public information, but the real draw were the anecdotes: his own reminiscences, and those of people he knew who knew Bohr well.
The other talks covered interesting ground: from deep approaches to quantum field theory, to new tools to understand black holes, to the implications of causality itself. One out of the ordinary talk was by Sabrina Pasterski, who advocated a new model of physics funding. I liked some elements (endowed organizations to further a subfield) and am more skeptical of others (mostly involving NFTs). Regardless it, and the rest of the conference more broadly, spurred a lot of good debate.
Today, we’d call Leibniz a mathematician, a physicist, and a philosopher. As a mathematician, Leibniz turned calculus into something his contemporaries could actually use. As a physicist, he championed a doomed theory of gravity. In philosophy, he seems to be most remembered for extremely cheaty arguments.
Free will and determinism? Can’t it just be a coincidence?
I don’t blame him for this. Faced with a tricky philosophical problem, it’s enormously tempting to just blaze through with an answer that makes every subtlety irrelevant. It’s a temptation I’ve succumbed to time and time again. Faced with a genie, I would always wish for more wishes. On my high school debate team, I once forced everyone at a tournament to switch sides with some sneaky definitions. It’s all good fun, but people usually end up pretty annoyed with you afterwards.
People were annoyed with Leibniz too, especially with his solution to the problem of evil. If you believe in a benevolent, all-powerful god, as Leibniz did, why is the world full of suffering and misery? Leibniz’s answer was that even an all-powerful god is constrained by logic, so if the world contains evil, it must be logically impossible to make the world any better: indeed, we live in the best of all possible worlds. Voltaire famously made fun of this argument in Candide, dragging a Leibniz-esque Professor Pangloss through some of the most creative miseries the eighteenth century had to offer. It’s possibly the most famous satire of a philosopher, easily beating out Aristophanes’ The Clouds (which is also great).
Physicists can also get accused of cheaty arguments, and probably the most mocked is the idea of a multiverse. While it hasn’t had its own Candide, the multiverse has been criticized by everyone from bloggers to Nobel prizewinners. Leibniz wanted to explain the existence of evil, physicists want to explain “unnaturalness”: the fact that the kinds of theories we use to explain the world can’t seem to explain the mass of the Higgs boson. To explain it, these physicists suggest that there are really many different universes, separated widely in space or built in to the interpretation of quantum mechanics. Each universe has a different Higgs mass, and ours just happens to be the one we can live in. This kind of argument is called “anthropic” reasoning. Rather than the best of all possible worlds, it says we live in the world best-suited to life like ours.
I called Leibniz’s argument “cheaty”, and you might presume I think the same of the multiverse. But “cheaty” doesn’t mean “wrong”. It all depends what you’re trying to do.
Leibniz’s argument and the multiverse both work by dodging a problem. For Leibniz, the problem of evil becomes pointless: any evil might be necessary to secure a greater good. With a multiverse, naturalness becomes pointless: with many different laws of physics in different places, the existence of one like ours needs no explanation.
In both cases, though, the dodge isn’t perfect. To really explain any given evil, Leibniz would have to show why it is secretly necessary in the face of a greater good (and Pangloss spends Candide trying to do exactly that). To explain any given law of physics, the multiverse needs to use anthropic reasoning: it needs to show that that law needs to be the way it is to support human-like life.
This sounds like a strict requirement, but in both cases it’s not actually so useful. Leibniz could (and Pangloss does) come up with an explanation for pretty much anything. The problem is that no-one actually knows which aspects of the universe are essential and which aren’t. Without a reliable way to describe the best of all possible worlds, we can’t actually test whether our world is one.
The same problem holds for anthropic reasoning. We don’t actually know what conditions are required to give rise to people like us. “People like us” is very vague, and dramatically different universes might still contain something that can perceive and observe. While it might seem that there are clear requirements, so far there hasn’t been enough for people to do very much with this type of reasoning.
However, for both Leibniz and most of the physicists who believe anthropic arguments, none of this really matters. That’s because the “best of all possible worlds” and “most anthropic of all possible worlds” aren’t really meant to be predictive theories. They’re meant to say that, once you are convinced of certain things, certain problems don’t matter anymore.
Leibniz, in particular, wasn’t trying to argue for the existence of his god. He began the argument convinced that a particular sort of god existed: one that was all-powerful and benevolent, and set in motion a deterministic universe bound by logic. His argument is meant to show that, if you believe in such a god, then the problem of evil can be ignored: no matter how bad the universe seems, it may still be the best possible world.
Similarly, the physicists convinced of the multiverse aren’t really getting there through naturalness. Rather, they’ve become convinced of a few key claims: that the universe is rapidly expanding, leading to a proliferating multiverse, and that the laws of physics in such a multiverse can vary from place to place, due to the huge landscape of possible laws of physics in string theory. If you already believe those things, then the naturalness problem can be ignored: we live in some randomly chosen part of the landscape hospitable to life, which can be anywhere it needs to be.
So despite their cheaty feel, both arguments are fine…provided you agree with their assumptions. Personally, I don’t agree with Leibniz. For the multiverse, I’m less sure. I’m not confident the universe expands fast enough to create a multiverse, I’m not even confident it’s speeding up its expansion now. I know there’s a lot of controversy about the math behind the string theory landscape, about whether the vast set of possible laws of physics are as consistent as they’re supposed to be…and of course, as anyone must admit, we don’t know whether string theory itself is true! I don’t think it’s impossible that the right argument comes around and convinces me of one or both claims, though. These kinds of arguments, “if assumptions, then conclusion” are the kind of thing that seems useless for a while…until someone convinces you of the conclusion, and they matter once again.
So in the end, despite the similarity, I’m not sure the multiverse deserves its own Candide. I’m not even sure Leibniz deserved Candide. But hopefully by understanding one, you can understand the other just a bit better.
The Niels Bohr Institute is hosting a conference this week on New Ideas in Cosmology. I’m no cosmologist, but it’s a pretty cool field, so as a local I’ve been sitting in on some of the talks. So far they’ve had a selection of really interesting speakers with quite a variety of interests, including a talk by Roger Penrose with his trademark hand-stippled drawings.
Including this old classic
One thing that has impressed me has been the “interdisciplinary” feel of the conference. By all rights this should be one “discipline”, cosmology. But in practice, each speaker came at the subject from a different direction. They all had a shared core of knowledge, common models of the universe they all compare to. But the knowledge they brought to the subject varied: some had deep knowledge of the mathematics of gravity, others worked with string theory, or particle physics, or numerical simulations. Each talk, aware of the varied audience, was a bit “colloquium-style“, introducing a framework before diving in to the latest research. Each speaker knew enough to talk to the others, but not so much that they couldn’t learn from them. It’s been unexpectedly refreshing, a real interdisciplinary conference done right.






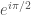 , and
, and 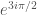 , and everything else you can write as
, and everything else you can write as  . However, 0 is still not a vacuum value. Neither is, for example,
. However, 0 is still not a vacuum value. Neither is, for example,  .
.